Video Search#
The application is built on a modular microservices approach using the LangChain framework.

*Figure 1: Video Search mode system architecture
Pipeline Components#
The following are the Video Search pipeline’s components:
Video Search UI: You can use the reference UI to interact with and raise queries to the Video Search sample application. You can mark a query to run in the background for the current video corpus or all incoming videos.
Visual Data Prep. microservice: The sample Visual Data Prep. microservice allows ingestion of video from the object store. The ingestion process creates embeddings of the videos and stores them in the preferred vector database. The modular architecture allows you to customize the vector database. The sample application uses the Visual Data Management System (VDMS) database. The raw videos are stored in the MinIO object store, which is also customizable.
Video Search backend microservice: The Video Search backend microservice embeds user queries and generates responses based on the search result. The vector database is queried for a best match in the embedding space.
Embedding inference microservice: The OpenVINO™ toolkit-based microservice runs embedding models on the target Intel® hardware.
Reranking inference microservice: Though an option, the reranker is currently not used in the pipeline. The OpenVINO™ model server runs the reranker models.
Note: Although the reranker is shown in the figure, support for the reranker depends on the vector database used. The default Video Search pipeline uses the VDMS vector database, where there is no support for the reranker. See details on the system architecture below.
Detailed Architecture#
The Video Search pipeline combines core LangChain application logic and a set of microservices. The following figures show the architecture.
Video Ingestion Architecture#

Video Query Architecture#

The Video Search UI communicates with the Video Search backend microservice. The Embedding microservice is provided as part of Intel’s Edge AI inference microservices catalog, supporting open-source models that can be downloaded from model hubs, for example Hugging Face Hub models that integrate with OpenVINO™ toolkit.
The Visual Data Prep. microservice ingests common video formats, converts them into embedding space, and store them in the vector database. You can also save a copy of the video to the object store.
Application Flow#
Input Sources:
Videos: The Visual Data Prep. microservice ingests common video formats. Currently, the ingestion only supports video files; it does not support live-streaming inputs.
Create Context
Upload input videos: The UI microservice allows you to interact with the application through the defined application API, and provides an interface for you to upload videos. The application stores the videos in the MinIO database. Videos can be ingested continuously from pre-configured folder locations, for surveillance scenarios.
Convert to embeddings space: The Video Ingestion microservice creates the embeddings from the uploaded videos using the embedded microservice. The application stores the embeddings in Visual Data Management System (VDMS).
Query Flow
Input a query: The UI microservice provides a prompt window for user queries that can be saved. You can enable up to eight queries to run in the background continuously on any new video being ingested. This is a critical capability for agentic reasoning.
Execute the Video Search pipeline: The Video Search backend microservice does the following to generate the output response:
Converts the query into an embedding space using the Embeddings microservice.
Does a semantic retrieval to fetch the relevant videos from the vector database. Currently, the top-k (with k being configurable) video is used. Does not use a reranker microservice currently.
Generate the Output:
Response: The application sends the search results, including the retrieved video from object store, to the UI.
Observability dashboard: If set up, the dashboard displays real-time logs, metrics, and traces, which shows the application’s performance, accuracy, and resource consumption.
The following figure shows the application flow, including the APIs and data sharing protocols:
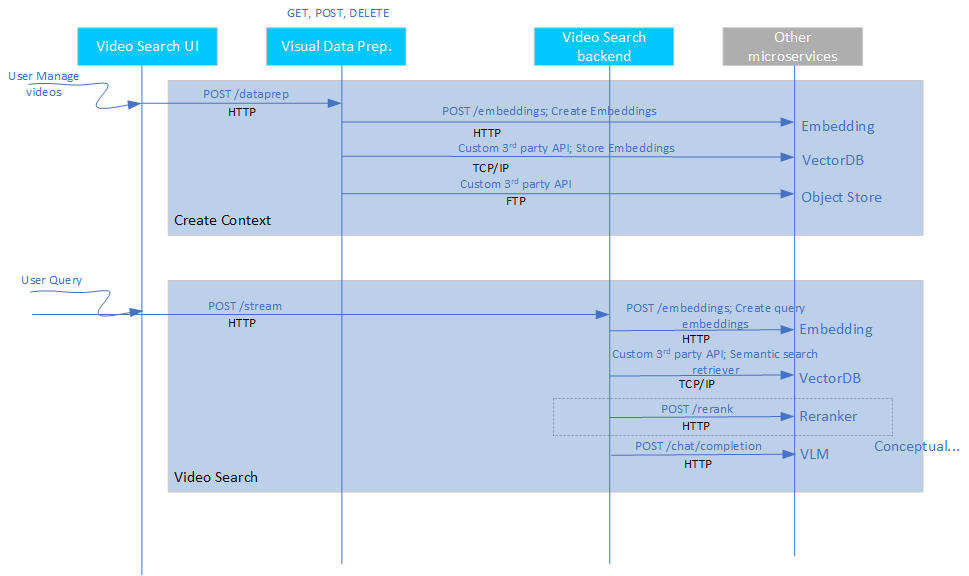
*Data flow for Video Search mode
Key Components and Their Roles#
The key components of the Video Search mode are as follows:
Intel’s Edge AI Inference microservices:
What it is: Inference microservices are the embeddings and reranker microservices that run the chosen models on the hardware, optimally.
How it is used: Each microservice uses OpenAI APIs to support their functionality. The microservices are configured to use the required models and are ready. The Video Search backend accesses these microservices in the LangChain application, which creates a chain out of these microservices.
Benefits: Intel guarantees that the sample application’s default microservices configuration is optimal for the chosen models and the target deployment hardware. Standard OpenAI APIs ensure easy portability of different inference microservices.
Visual Data Prep. microservice:
What it is: This microservice ingests videos, creates the necessary context, and retrieves the right context based on user query.
How it is used: Video ingestion microservice provides a REST API endpoint that can be used to manage the contents. The Video Search backend uses this API to access its capabilities.
Benefits: The core part of the video ingestion functionality is the vector handling capability that is optimized for the target deployment hardware. You can select the vector database based on performance considerations. You can treat this microservice as a reference implementation.
Video Search backend microservice:
What it is: Video Search backend microservice is a LangChain framework-based implementation of Video Search’s Retrieval-Augmented Generation (RAG) pipeline, which handles user queries.
How it is used: The UI frontend uses a REST API endpoint to send user queries and trigger the Video Search pipeline.
Benefits: This microservice provides a reference on using the LangChain framework through Intel’s Edge AI inference microservices.
Video Search UI:
What it is: A reference frontend interface for you to interact with the Video Search pipeline.
How it is used: The UI microservice runs on the deployed platform on a certain configured port. You can access the specific URL to use the UI.
Benefits: You can treat this microservice as a reference implementation.
Extensibility#
The Video Search mode is modular and allows you to:
Change inference microservices:
The default option is OpenVINO™ model server. You can use other model servers, for example the Virtual Large Language Model (vLLM) with OpenVINO model server as backend, and the Text Generation Inference (TGI) toolkit to host Embedding and Vision-Language Models (VLMs) but Intel has not validated this method.
The compulsory requirement is OpenAI API compliance. Intel does not guarantee that other model servers can provide the same performance compared to the default options.
Load different embedding and reranker models:
Use models from Hugging Face Hub that integrate with OpenVINO toolkit, or from vLLM model hub. The models are passed as parameters to the corresponding model servers.
Use other generative AI frameworks like the Haystack framework and LlamaIndex tool:
Integrate the inference microservices into an application backend developed on other frameworks similar to the LangChain framework integration provided in this sample application.
Deploy on diverse target Intel® hardware and deployment scenarios:
Follow the system requirements guidelines on the options available.