Multi-level Video Understanding Microservice#
This microservice delivers a novel approach to video summarization. By employing a configurable, multi-level architecture and enhanced temporal modeling, it progressively analyzes video content to generate significantly more accurate and context-aware summaries.
The overall high-level design is shown as below:
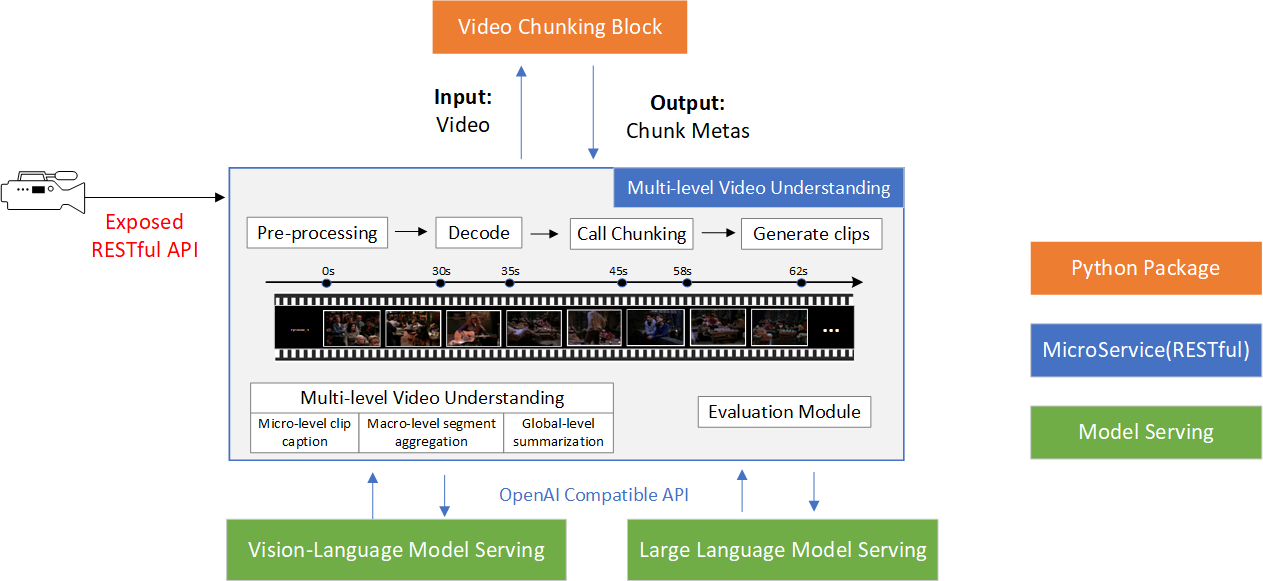
Figure 1: Multi-level Video Understanding High-level Design
Among all the components, Multi-level Video Understanding refers to this microservice.
Video Chunking is a library implemented in this Open Edge Platform (OEP) suite:
video-chunking-utils.
Vision-Language Model Serving and Large Language Model Serving are dependent
services required by this microservice, running on OpenAI-compatible APIs.
Overview#
To handle long video summarization, we design a multi-level framework where each level operates via a recurrent approach, effectively control the context length to improve computational efficiency and comply with model constraints or GPU memory constraints.
This framework operates in three stages:
Detects scene-switch boundaries to segment the long video into chunks.
Uses VLM to generate captions for each of these short video clips.
Uses LLM hierarchically and recurrently aggregates the textual captions to a coherent global summary. A dedicated temporal enhancement component is employed at each level to strengthen the connections between units.
Features
Feature 1: Process video from local files or http(s) links.
Feature 2: Automatic model download and conversion on startup.
Feature 3: Containerization with Docker.
Feature 4: RESTful API with FastAPI with support for concurrent requests.
Feature 5: Support specify video chunking method in user requests.
Feature 6: Support specify multi-level settings in user requests.
Feature 7: Support specify temporal enhancement settings in user requests.
Feature 8: Designed to work effortlessly with GenAI model servings that provide OpenAI-compatible APIs.
Feature 9: Support subtitle-aware summarization — pass subtitles alongside a video for extra per-chunk context, or run caption-only (
video: "none"+ subtitles) to summarize a pre-built event log without any VLM inference.Feature 10: Support runtime-registered dynamic prompt tasks via the
/v1/tasksAPI, in addition to the built-insummary/summary_zhtasks.
How It Works#
The Multi-level Video Understanding microservice unlocks straightforward video summarization. Users simply submit a video file. The service then seamlessly analyzes the content through its intelligent, multi-level framework to generate a summary, which is returned directly to the client. A comprehensive RESTful API is provided to access and control key features.
Models supported#
The service automatically downloads and manages the required models based on configuration. Any OpenAI-compatible model servings are supported.
Validated Models#
The following models are validated by the service:
Model ID |
Description |
Parameters |
HF link |
|---|---|---|---|
Qwen/Qwen3.5-35B-A3B |
Multimodal (serves VLM + LLM roles) |
~35B total / ~3B active |
For the on-device deployment a single Qwen3.5-35B-A3B endpoint fills both the VLM and LLM roles. Any OpenAI-compatible serving is supported, so separate VLM and LLM models can still be configured via VLM_BASE_URL / LLM_BASE_URL.