Data Ingestion microservice#
Data ingestion service loads, parses, and creates embeddings for popular document types like pdf, docx, and txt files. The data ingestion is implemented as a microservice which in turn interacts with other microservices, namely vectorDB, data store, and embedding to achieve the functionality. The ingested documents are converted to embeddings, embeddings stored in the vectorDB, and source documents stored in the data store. PGVector is used as the vectorDB and minIO is used as the data store.
Key Benefits:
This microservice provides necessary abstraction with 3rd party vectorDB and data store making it easy to integrate other providers.
The microservice provides support for handling popular document types. It is also a place holder for necessary extensions to add additional document types.
The selected components to implement the functionality is benchmarked and validated for optimal performance.
Example Use Case#
Use Case 1: Refer to the Chat Q&A sample application where this microservice is used.
High-Level System View Diagram#
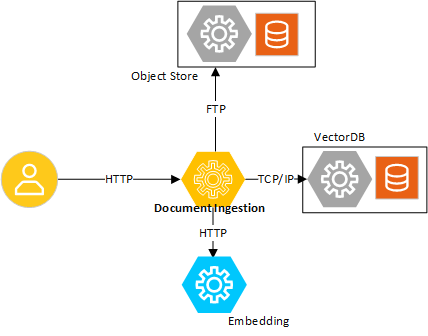
Figure 1: High-level system view demonstrating the microservice in a real-world use case.
Key Features#
The user manages the documents using REST APIs supported by the microservice. The APIs allow the user to upload, delete, and read the documents managed by the microservice.
The microservice uses PGVector as the vectorDB. However, implementation is modular to support other vectorDBs.