Intel® LLM Library for PyTorch#
Intel® LLM Library for PyTorch (IPEX-LLM) is an LLM optimization library which accelerates local LLM inference and fine-tuning (LLaMA, Mistral, ChatGLM, Qwen, DeepSeek, Mixtral, Gemma, Phi, MiniCPM, Qwen-VL, MiniCPM-V, etc.) on Intel XPU (CPU, iGPU, NPU, dGPU).
Model List shows the optimized/verified models on IPEX-LLM with state-of-art LLM optimizations, XPU acceleration and low-bit (FP8/FP6/FP4/INT4) support. Also, IPEX-LLM provides seamless integration with llama.cpp, Ollama, HuggingFace transformers, LangChain, LlamaIndex, vLLM, Text-Generation-WebUI, DeepSpeed-AutoTP, FastChat, Axolotl, HuggingFace PEFT, HuggingFace TRL, AutoGen, ModeScope, etc.
|
|
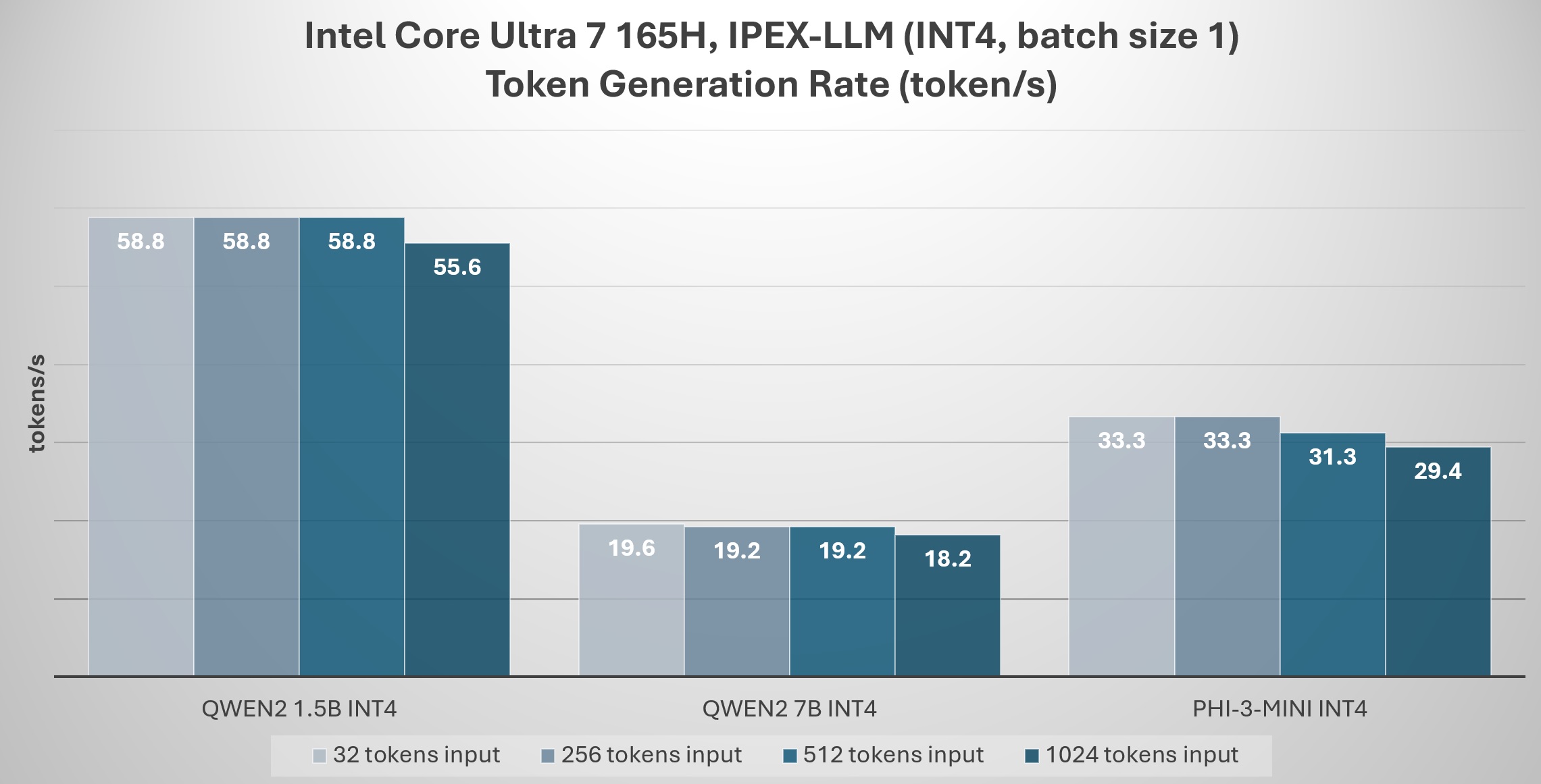
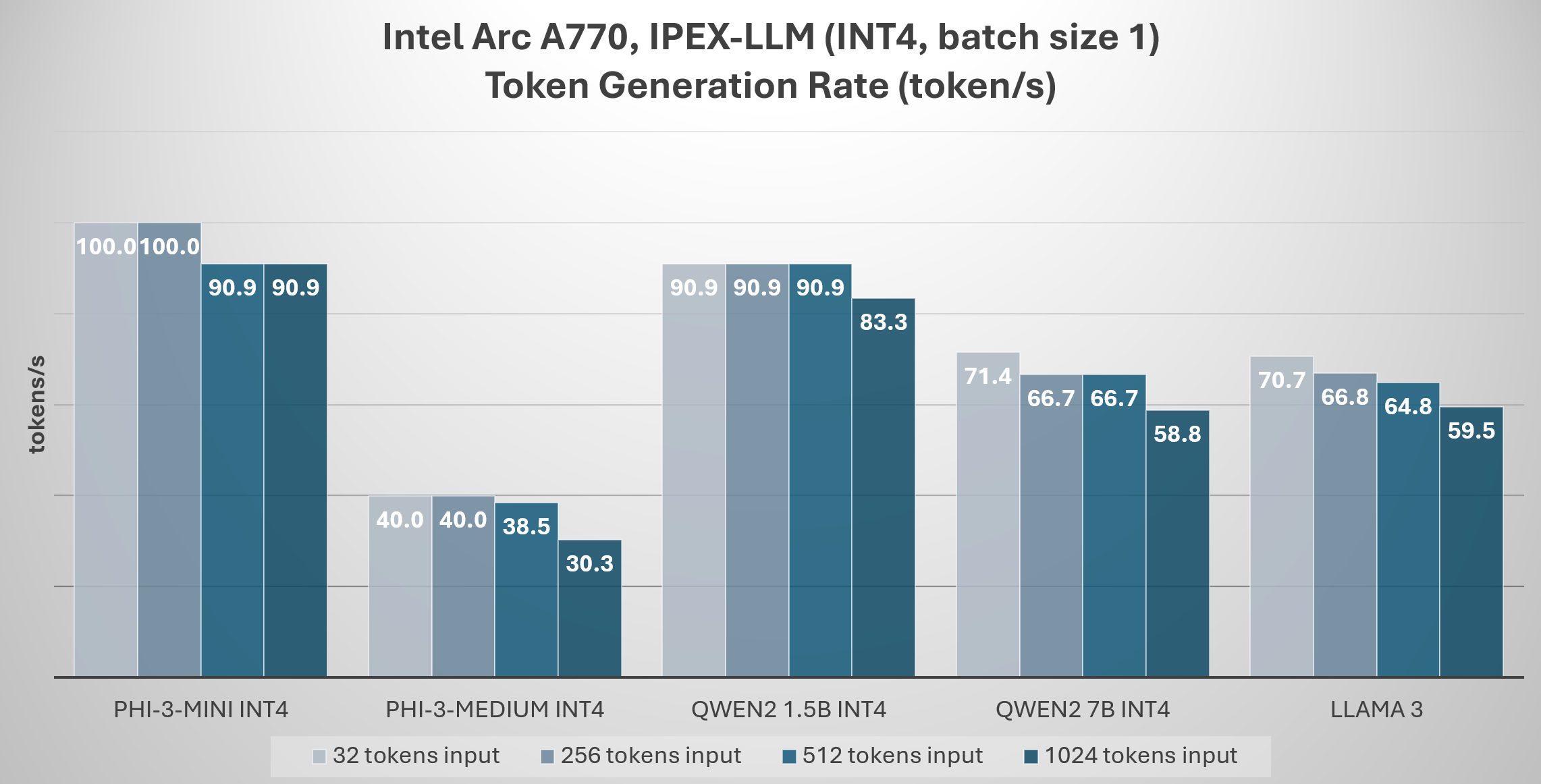
For robotics software developers, IPEX-LLM offers the opportunity to empower the development of new applications that combine robotics with LLMs, helping LLMs achieve better performance on Intel® platforms.
For details, see: ipex-llm.
Before installing Intel® LLM Library for PyTorch, ensure to complete the environment setup in Get Started and have Intel® oneAPI™ Base Toolkit installed. Then, install Intel® LLM Library for PyTorch in your Python environment:
pip install --pre --upgrade ipex-llm[xpu]==2.2.0b2 --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/cn/