Video Summarization Overview#
The Video Summarization mode enables concise and informative summaries of long-form videos. It uses Generative AI Vision Language Models (VLMs), which leverages advanced AI techniques to combine visual, audio, and textual data to understand and extract relevant content from videos, thereby, enabling efficient content review and improved searchability.
The Video Summarization mode provides a rich response by using Intel’s AI systems and Intel’s Edge AI microservices catalog.
You can develop, customize, and deploy Video Summarization solutions in diverse deployment scenarios with out-of-the-box support for on-premise and edge environments.
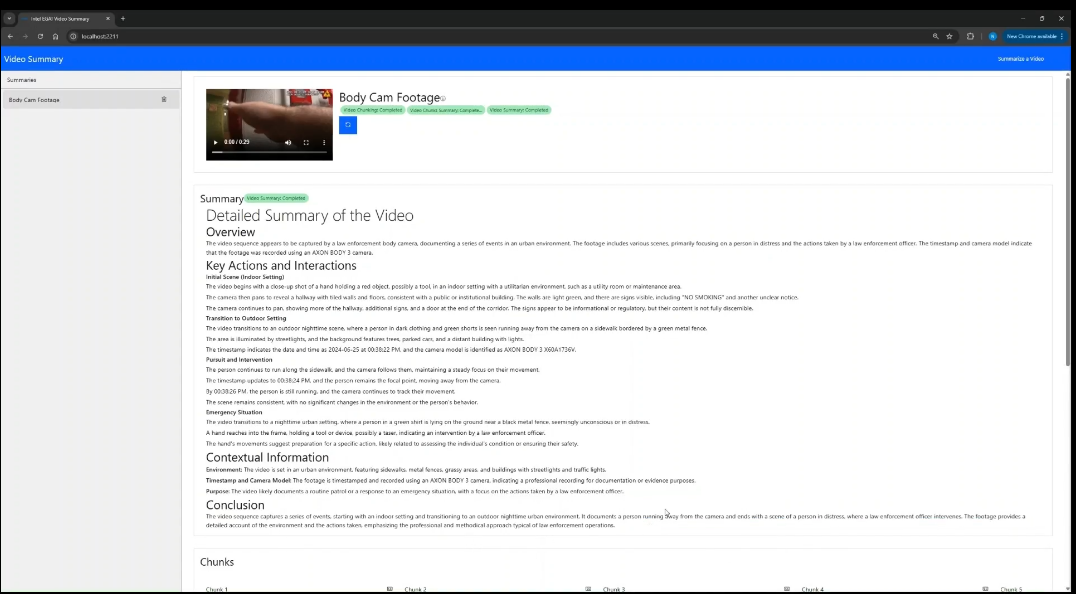
The following is the Video Summarization mode UI:
Purpose#
The Video Summarization mode allows you to customize the accuracy-performance trade-off. The following figure shows an example of pipeline configurations with different compute requirements.
The following figure shows sample Video Summarization pipeline configurations:
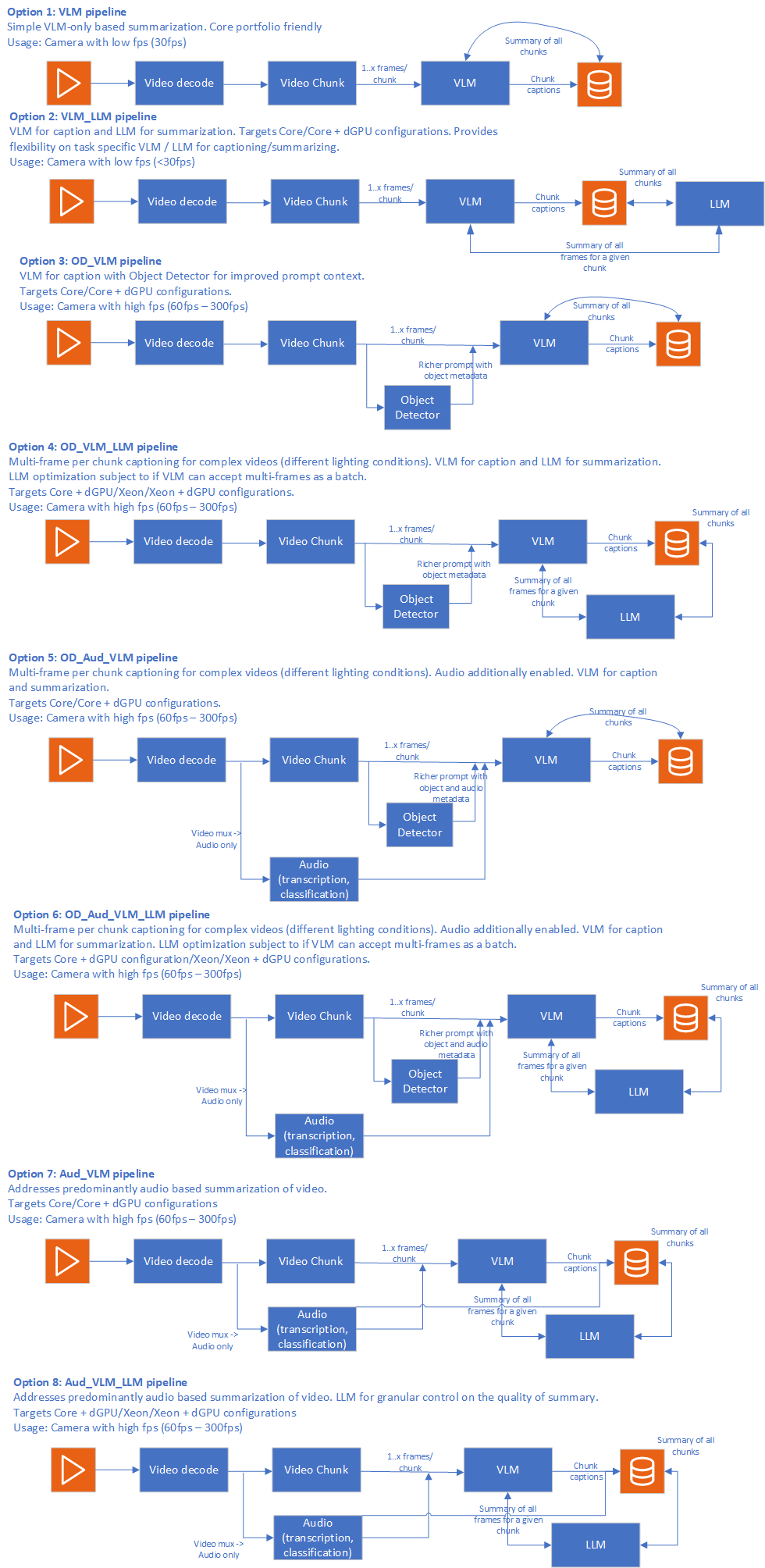 *Sample Video Summarization pipeline configurations
*Sample Video Summarization pipeline configurations
To create a summary with the best possible accuracy for a given compute, the Video Summarization mode:
Allows you to build the video summarization pipeline quickly through Intel’s Edge AI catalog of inference microservices. The inference microservices are optimized for Intel’s Edge AI systems.
Serves as a blueprint for building similar scalable and modular solutions that can be deployed on Intel’s Edge AI systems.
Showcases the competitiveness of Intel’s Edge AI systems to address varied deployment scenarios, from the edge to the cloud.
Provides reference sample microservices for capabilities like video ingestion and UI frontend, which reduces the effort to customize the application.
Key Features#
User-Friendly and Intuitive: You can use natural language through the easy-to-use interface to search.
Richer contextual and perceptual understanding: The Video Summarization mode provides a richer contextual and perceptual understanding of the video through multimodal embedding. For example, you can use an object detector to enrich the quality of input to Vision-Language Model (VLM) captioning. See the architecture overview.
Optimized systems: The pipeline runs on Intel’s Edge AI systems, ensuring high performance, reliability, and low cost of ownership.
Flexible Deployment Options: You can choose the deployment environment, for example, deploying using the Docker Compose tool and Helm charts.
Support for open-source Models: You can use the desired generative AI models, for example, VLM and embeddings. The Video Summarization mode supports various open-source models, for example, the Hugging Face Hub models that integrate with OpenVINO™ toolkit, allowing you to select the best models for their use cases.
Self-Hosting: You can perform the inference locally or on-premises, ensuring data privacy and reducing latency.
Observability and monitoring: The Video Summarization mode provides observability and monitoring capabilities using OpenTelemetry telemetry & OpenLIT platform, enabling you to monitor the application’s performance and health in real-time.
Scalability: The pipeline can handle large volumes of video data, making it suitable for various applications, including media analysis, content management, and personalized recommendations.
Natural Language Querying: The captions generated by the application allow you to search for video content using natural language, making the search process intuitive and user-friendly. This capability combines the Video Summarization pipeline with the Video Search pipeline.
Audio capability: For certain videos, the audio provides a richer context, which can improve the accuracy of the summary. The audio pipeline will transcribe the audio channel and use the same as additional context information for the VLM.
Efficient Summarization: You can generate summaries of videos and highlight key moments.
Customizable: You can customize the pipeline, for example, to focus on particular topics or themes within the video, or to enable context extraction from audio, before embedding and indexing.
How to Use the Application Effectively#
The Video Summarization pipeline offers features to improve accuracy for complex, long-form videos. Choosing which features to use involves balancing accuracy and performance. You can configure the pipeline based on answers to the following key questions, to determine the trade-off between accuracy and compute:
1. How complex is the video?
2. What is the pipeline's accuracy target, as measured by key qualitative metrics like the BERT score and by manual inspection?
3. What are the available compute resources for running the pipeline?
4. What are the key performance metrics, for example, throughput and latency, that the pipeline needs to achieve?
After configuring the pipeline, you can deploy the application, upload the video to be summarized, set parameters like chunk duration and frame count, and then submit the request. The application updates you on the progress and provides the final summary. The API specification outlines how to access the application’s features.
Detailed hardware and software requirements are available here.
To get started with the application, see the Get Started page.