Video Search Overview#
You can search through videos using natural language, where the search is done in the background. When the Video Search pipeline finds a match, it raises events or notifications. The Video Search mode uses multimodal embedding and agentic reasoning, which improves accuracy and efficiency. Example use cases are video forensics, media analysis, content management, and personalized recommendations.
The Video Search mode uses a foundational retrieval-augmented generation (RAG) pipeline for video data. The Video Search mode provides a rich response by using Intel’s AI systems and Intel’s Edge AI microservices catalog.
You can develop, customize, and deploy Video Summarization solutions in diverse deployment scenarios with out-of-the-box support for on-premise and edge environments.
The following is the Video Search mode UI:
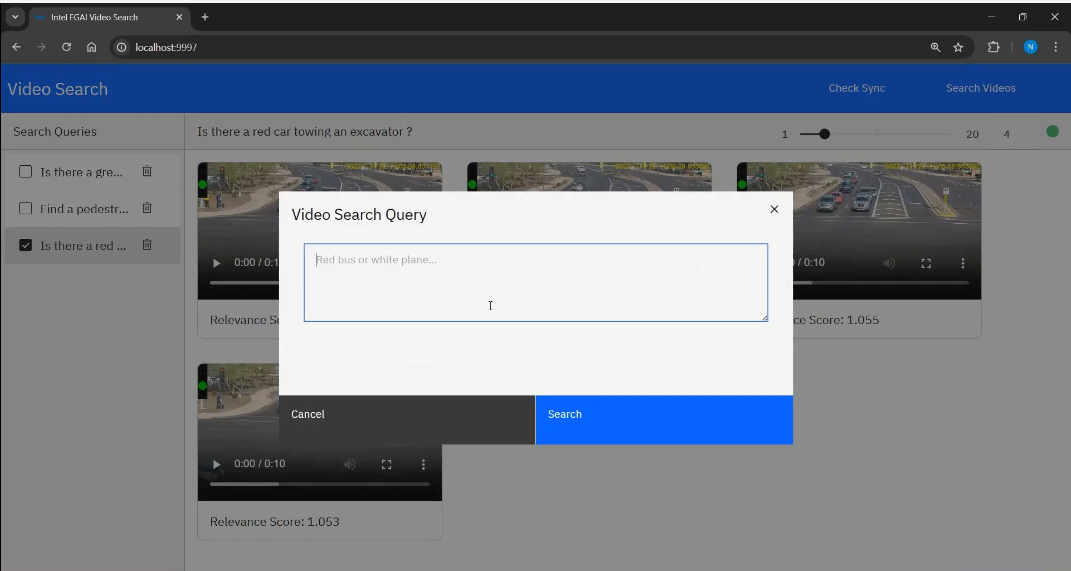
Purpose#
The Video Search mode:
Allows you to build the video search pipeline quickly through Intel’s Edge AI catalog of inference microservices. The inference microservices are optimized for Intel’s Edge AI systems.
Serves as a blueprint for building similar scalable and modular solutions that can be deployed on Intel’s Edge AI systems.
Showcases the competitiveness of Intel’s Edge AI systems to address varied deployment scenarios, from the edge to the cloud.
Provide reference sample microservices for capabilities like video ingestion and UI frontend, which reduces the effort to customize the application.
Showcase how popular frameworks like the LangChain framework can be used to implement or customize the Video Search pipeline quickly and deploy the pipeline on Intel’s Edge AI systems.
Key Features#
User-Friendly and Intuitive: You can use natural language through the easy-to-use interface to search.
Richer contextual and perceptual understanding: The Video Search mode provides a richer contextual and perceptual understanding of the video through multimodal embedding.
Optimized systems: The pipeline runs on Intel’s Edge AI systems, ensuring high performance, reliability, and low cost of ownership. See system requirements for the list of hardware on which the pipeline is validated and optimized.
Flexible Deployment Options: You can choose the deployment environment, for example, deploying using the Docker Compose tool and Helm charts.
Support for open-source Models:You can use the desired generative AI models, for example, VLM and embeddings. The Video Search pipeline supports various open-source models, for example the [Hugging Face Hub models that integrate with OpenVINO™ toolkit], allowing developers to select the best models for their use cases.
Self-Hosting:You can perform the inference locally or on-premises, ensuring data privacy and reducing latency.
Observability and monitoring: The application provides observability and monitoring capabilities using OpenTelemetry* APIs, SDKs, and tools & OpenLIT platform, enabling developers to monitor the application’s performance and health in real-time.
Agentic Reasoning and Event Generation: The Video Search pipeline decomposes user queries, plans and executes multi-stage retrievals, and generates or tracks events based on query results. When a match is found, the application raises events or notifications.
Customizable: You can customize components of the pipeline, for example, video ingestion, model selection, and deployment options. You can also customize Intel’s Edge AI inference microservices.
How to Use the Application Effectively#
The Video Search mode consists of two main functionalities:
The Video Ingestion functionality uses the Video Ingestion microservice that supports common video formats, to add videos to the application. The ingestion uses the Embedding microservice to create video embeddings, and stores the video embeddings in the preferred vector database. The modular architecture allows you to customize the vector database.
Generation (Search Results): The Generation functionality allows you to query the video database and generate responses. The VLM inference microservice, embedding inference microservice, and reranking microservice work together to provide accurate and efficient answers to user queries.
When you submit a question, the embedding model transforms it into an embedding, enabling semantic comparison with stored document embeddings. The vector database searches for relevant embeddings, returning a ranked list of documents based on semantic similarity. The VLM inference microservice generates a context-aware response from the final set of ranked videos.
To use the application:
Upload the videos using the ingestion block or the ingestion APIs exposed by the application.
Query the video for specific events using natural language. The application returns a set of videos that match the query.
For detailed hardware and software requirements, see System Requirements.
To get started with the application, see the Get Started page.