How to publish metadata to InfluxDB#
Steps#
DL Streamer Pipeline Server supports storing metadata of frames in InfluxDB.
First you must add server configuration details such as host, port, credentials, etc. as environment variables to DL Streamer Pipeline Server.
If you are launching the service along with DL Streamer Pipeline Server, you should add the
InfluxDB service details to DL Streamer Pipeline Server’s docker-compose.yml file present at
[WORKDIR]/edge-ai-libraries/microservices/dlstreamer-pipeline-server/docker/docker-compose.yml.
For this tutorial we will be following this approach.
For the sake of demonstration, we will be using InfluxDB v2.7.11 to store the metadata and will be launched together with DL Streamer Pipeline Server. To get started, follow the steps below.
Modify environment variables in
[WORKDIR]/edge-ai-libraries/microservices/dlstreamer-pipeline-server/docker/.envfile.Provide the InfluxDB details and credentials.
INFLUXDB_HOST=influxdb INFLUXDB_PORT=8086 INFLUXDB_USER=<DATABASE USERNAME> #example INFLUXDB_USER=influxadmin INFLUXDB_PASS=<DATABASE PASSWORD> #example INFLUXDB_PASS=influxadmin
Add influxdb service to the docker compose yml.
Modify the docker-compose.yml file with the following changes. Add
influxdbservice underservicessection. Modify the values as per your requirements.services: influxdb: image: influxdb:latest container_name: influxdb hostname: influxdb ports: - "8086:8086" volumes: - influxdb:/var/lib/influxdb restart: unless-stopped networks: - app_network
Also add the
influxdbin volume section of your docker-compose.ymlvolumes: vol_pipeline_root: driver: local driver_opts: type: tmpfs device: tmpfs influxdb:
A sample config has been provided for this demonstration at
[WORKDIR]/edge-ai-libraries/microservices/dlstreamer-pipeline-server/configs/sample_influx/config.json. We need to volume mount the sample config file in the[WORKDIR]/edge-ai-libraries/microservices/dlstreamer-pipeline-server/docker/docker-compose.ymlfile. Refer to the following snippet:volumes: # Volume mount [WORKDIR]/edge-ai-libraries/microservices/dlstreamer-pipeline-server/configs/sample_influx/config.json to config file that DL Streamer Pipeline Server container loads. - "../configs/sample_influx/config.json:/home/pipeline-server/config.json"
Start DL Streamer Pipeline Server and InfluxDB.
cd [WORKDIR]/edge-ai-libraries/microservices/dlstreamer-pipeline-server/docker docker compose up -d
Setup InfluxDB and create bucket.
DL Streamer Pipeline Server expects that the setup should be done for InfluxDB and also a bucket should also be created before launching the pipeline. Here is a sample Python script (requires
requestPython package). This script initializes an InfluxDB 2.x server by creating the first admin user, org, and bucket. It calls the/api/v2/setupendpoint with the required parameters. Adjust the credentials and names as needed before running.import requests url = "http://localhost:8086/api/v2/setup" payload = { "username": "influxadmin", "password": "influxadmin", "org": "my-org", "bucket": "dlstreamer-pipeline-results", "retentionPeriodSeconds": 0 } response = requests.post(url, json=payload) if response.status_code == 201: print("Setup successful!") else: print("Setup failed:", response.text)
Execute it in a Python environment that has
requestpackage installed. Save the Python script above asinflux_setup.pyin your current directory.python3 influx_setup.py
Launch pipeline by sending the following curl request.
curl http://localhost:8080/pipelines/user_defined_pipelines/pallet_defect_detection -X POST -H 'Content-Type: application/json' -d '{ "source": { "uri": "file:///home/pipeline-server/resources/videos/warehouse.avi", "type": "uri" }, "destination": { "metadata": { "type": "influx_write", "bucket": "dlstreamer-pipeline-results", "org": "my-org", "measurement": "dlsps" } }, "parameters": { "detection-properties": { "model": "/home/pipeline-server/resources/models/geti/pallet_defect_detection/deployment/Detection/model/model.xml", "device": "CPU" } } }'
The frame destination sub-config for
influx_writespecifies that the frame metadata will be written to an InfluxDB instance under the organizationmy-organd bucketdlstreamer-pipeline-results. All frame metadata will be recorded under the same measurement, which defaults todlspsif themeasurementfield is not explicitly provided. For example, frame metadata will be written to the measurementdlspsin the bucketdlstreamer-pipeline-resultswithin the organizationmy-org.
Note: DL Streamer Pipeline Server supports only writing of metadata to InfluxDB. It does not support creating, maintaining or deletion of buckets. It also does not support reading or deletion of metadata from InfluxDB. Also, as mentioned before DL Streamer Pipeline Server assumes that the user already has a InfluxDB with buckets configured.
Once you start DL Streamer Pipeline Server with the above changes, you should be able to see metadata written to InfluxDB. Since we are using InfluxDB 2.x for our demonstration, you can see the frames being written to InfluxDB by logging into InfluxDB console. You can access the console in your browser -
http://<INFLUXDB_HOST>:8086. Use the credentials specified above in the[WORKDIR]/docker/.envto login into console. After logging into console, you can go to your desired buckets and check the metadata stored.You can also use the Query Builder in the InfluxDB UI to write and run the following query to view all data written to InfluxDB:
from(bucket: "dlstreamer-pipeline-results") |> range(start: -3h) |> filter(fn: (r) => r["_measurement"] == "dlsps") |> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value") |> group() |> sort(columns: ["_time"])
Example of metadata stored in InfluxDB:
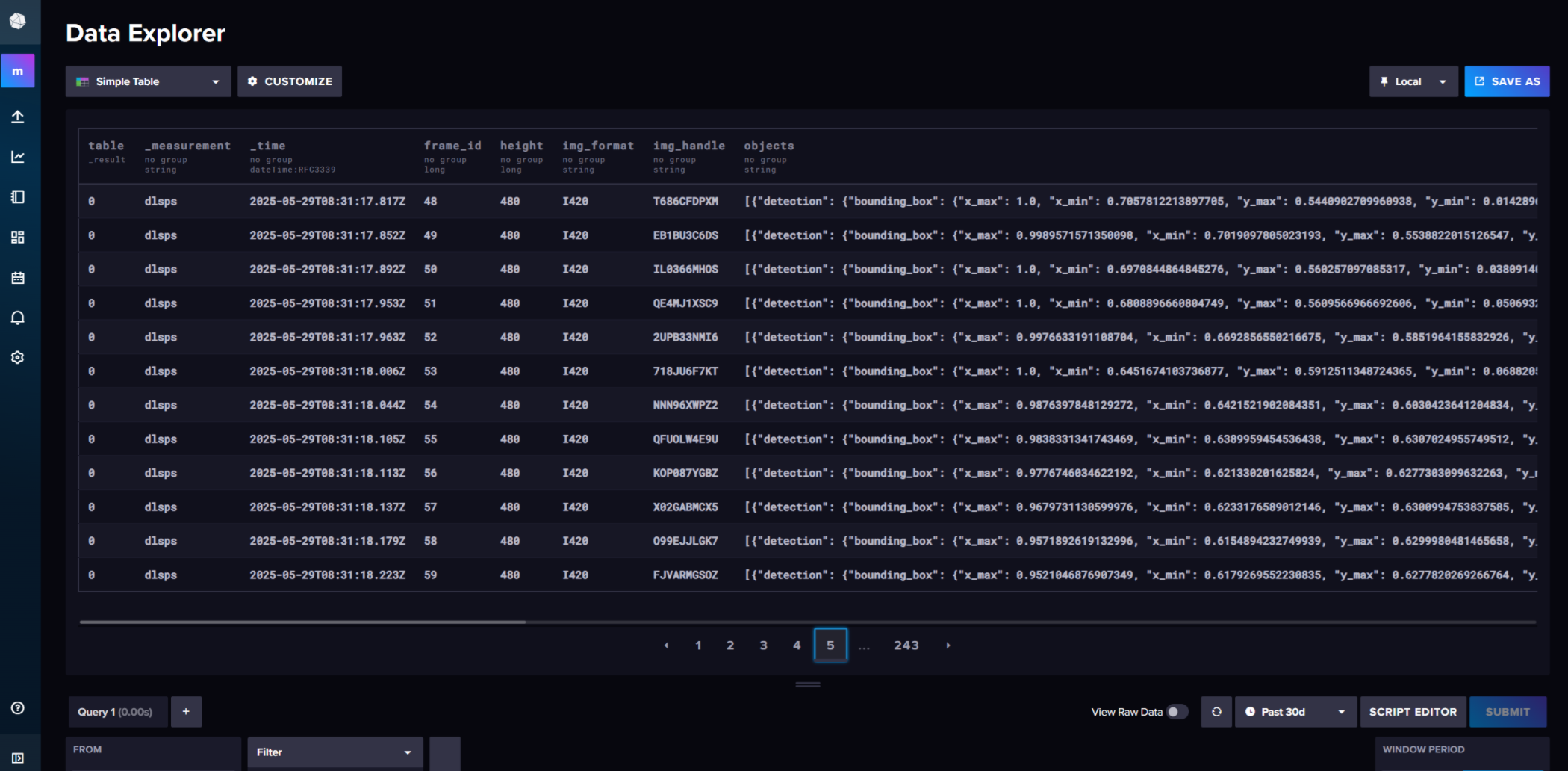
To stop DL Streamer Pipeline Server and other services, run the following. Since the data is stored inside the InfluxDB container for this demonstration, the metadata will not persists after the containers are brought down.
docker compose down -v