Video Search and Summarization Architecture Overview#
The Video Search and Summarization architecture is built on top of the Video Search and Video Summary architectures. This sections show how the components are reused to realize the combined mode.
Architecture#
The following figure shows the system architecture:

*Figure 1: Architecture of Video Search and Summarization sample application
The following are the components of the Video Search and Summarization pipeline. The combined mode uses components across the Video Search mode and the Video Summarization mode:
Video Search and Summarization UI: You can use the reference UI to interact with the Video Search and Summarization application, including uploading videos, searching, and viewing summaries.
Video pipeline manager: The pipeline manager is the central orchestrator of the Video Search and Summarization pipeline. It receives the requests from the UI and uses the other set of microservices to deliver the Video Search and Summarization capabilities. It can handle videos asynchronously while creating embeddings simultaneously for search indexing.
Video Ingestion: The Video Ingestion microservice, which is based on the Deep Learning Streamer (DL Streamer) pipeline, ingests common video formats that require search and summarization. The ingestion microservice creates video chunks, extracts configured frames from them, passes the frame(s) through object detection, and outputs the metadata and video chunks to the object store.
Multimodal Embedding Generation: The embedding microservice generates vector representations of video content - frames summary, captions summary, and audio transcriptions. The vector representations enable semantic search capabilities. These embeddings are created in parallel with the summaries and are stored in a vector database for retrieval.
VLM as the captioning block: The VLM microservice generates captions for a specific video chunk. The VLM accepts prompts that also include additional information from configured capabilities, such as object detection, and generates a caption. The caption information is stored in the object store and is also used to generate embeddings.
LLM as the summarizer of captions: The LLM microservice generates a summary of the individual captions. You can configure to use either the LLM or the VLM to generate the summaries.
Audio transcription: The Audio transcription microservice transcribes the audio channel in the given video. The extracted audio transcription serves as another source of metadata that can be used as an input to VLM, and separately as text data, to enrich the search and summary.
Video Search backend microservice: The Video Search backend microservice embeds user queries and generates responses based on the search result. The vector database is queried for a best match in the embedding space.
See details on the system architecture and customizable options here.
Note: Although the reranker is shown in the figure, support for the reranker depends on the vector database used. The default Video Search and Summarization pipeline uses the VDMS vector database, where there is no support for the reranker.
Detailed Architecture#
The following figure shows the architecture:
Architecture Diagram#
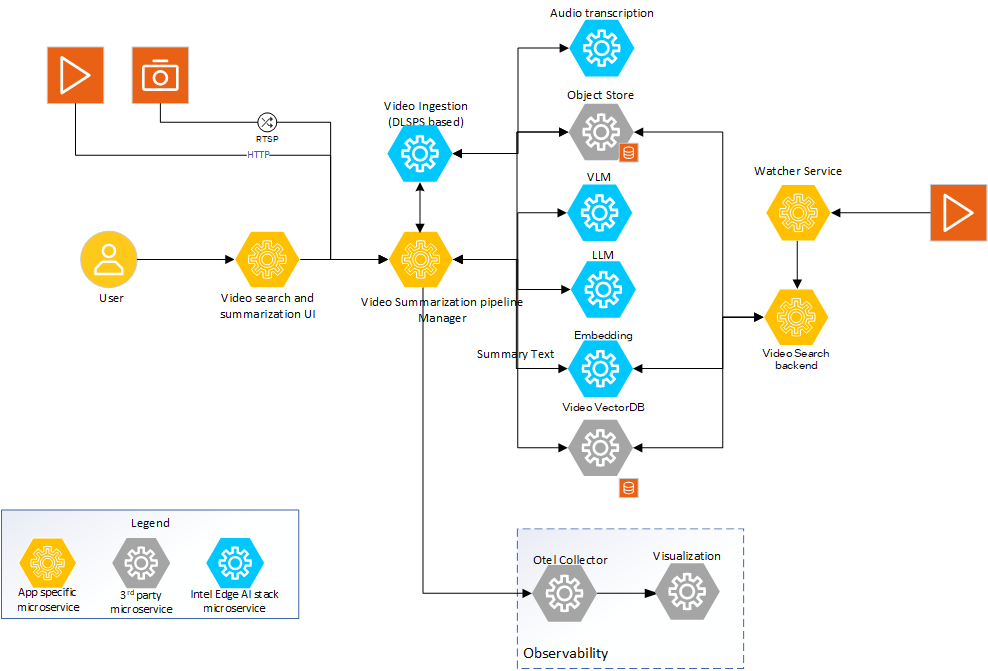
*Video Search and Summarization technical architecture
You can configure both the Video Search and Video Summarization pipelines, upload videos for processing, search semantically across videos, and view summaries through the Video Search and Summarization UI. The UI will then communicate with the pipeline manager.
The VLM, LLM, and Embedding microservices are provided as part of Intel’s Edge AI inference microservices catalog, supporting open-source models that can be downloaded from model hubs, for example, Hugging Face Hub models that integrate with OpenVINO™ toolkit.
The video ingestion microservice ingests common video formats, chunks the videos, and feeds the extracted frames into configurable capabilities, such as object detection. It then provides the outputs to the VLM microservice for captioning and to the embedding microservice for search indexing.
The LLM microservice provides final summaries of videos by summarizing the individual captions, while simultaneously converting the captions to embeddings and storing them in a vector database for semantic search. The audio transcription microservice uses the Whisper model to transcribe audio for search and summarization purposes. The raw videos, frames, and generated metadata are saved in the object store. The embeddings are stored in a vector database for a fast semantic search.
Application Flow#
The application flow involves the following steps for both search indexing and summarization:
Create the Video Search and Summarization pipeline
Configure the pipeline: The Video Search and Summarization UI microservice allows you to configure capabilities on the Video Search and Summarization pipeline. You can see configuration examples for the Video Summarization pipeline here.
Create the pipeline: The Video Summarization Pipeline Manager configures the pipeline based on your input.
Input Video Sources:
Provide video: You will provide the video to be summarized and searched. You can also configure the video through the UI. Currently, only offline video processing is supported through reading from local storage. In the future, live camera-streaming will be supported. The pipeline manager stores the video in a local object store.
Ingest video: The Video Ingestion microservice consumes the stored video. The microservices reuses the DL Streamer pipeline server and its capabilities to provide features such as object detection, audio classification, and (in future) input feed from live cameras. The ingestion process involves decoding, chunking, and selecting frame(s) from the input video. The extracted frame(s) is passed through object detection blocks, or the audio classification block if they are configured. The extracted frames and the metadata returned by the object detector and/or audio classification are then passed to the VLM microservice for captioning, and the embedding microservice for search indexing.
Audio transcription: The video is demuxed, and its audio extracted for transcription. The audio is fed to the Audio Transcription Microservice through the object store to create a transcription. This transcription is used to generate captions and embeddings for search, and is stored in the object store for later processing.
Create Caption for given frame(s) and Generate Embeddings
VLM microservice: The extracted frame(s) and the prompt and metadata returned from the object detector and/or audio classification are passed to vlm-ov-serving for captioning. Depending on the configuration and compute availability, batch captioning is also supported. To optimize for performance, captioning is done in parallel with video ingestion.
Embedding generation: The Multimodal Embedding microservice processes generated captions and metadata simultaneously to create vector representations that enable semantic search. These embeddings are stored in a vector database and indexed for fast retrieval.
VLM model selection: The VLM microservice’s capabilities depend on the VLM model used. For example, some models allow multi-frame captioning. The quality of the VLM output depends on the prompt you provide.
Store the captions and embeddings: The captions and metadata generated in the pipeline are stored in the local object store. The storage also maintains the necessary relationship information between the stored data. Concurrently, the embeddings are stored in the vector database with proper indexing for search.
Create a summary of all captions:
LLM microservice: The LLM microservice creates a summary of individual captions. The accuracy of the summary depends on the selected LLM model.
Enable semantic search capabilities:
Search functionality: Once embeddings are created and stored, you can search semantically across the entire video collection using natural language. The search system matches user queries against the stored embeddings to find semantically similar video content.
Unified interface: The UI provides summary viewing and search capabilities, allowing you to discover relevant videos through search, and then view their summaries.
Observability dashboard:
If set up, the dashboard displays real-time logs, metrics, and traces that provide a view of the application’s performance, accuracy, and resource consumption.
Key Components and Their Roles#
The key components of Video Search and Summarization mode are as follows:
Intel’s Edge AI Inference microservices:
What it is: Inference microservices are the VLM, LLM, audio transcription, and multimodal embedding microservices that run the chosen models optimally on the hardware.
How it is used: Each microservice uses OpenAI APIs to support its functionality. The microservices are configured to use the required models and are ready. The video pipeline manager accesses these microservices through the APIs for summary generation and search indexing.
Benefits: Intel guarantees that the sample application’s default microservices configuration is optimal for the chosen models and the target deployment hardware. Standard OpenAI APIs ensure easy portability of different inference microservices.
Video Ingestion microservice:
What it is: Video Ingestion microservice, which reuses DL Streamer pipeline server, can ingest videos, extract audio, create chunks, detect objects, classify audio, and feed extracted raw information and generated metadata to Video Search and Video Summarization indexing stages.
How it is used: This microservice provides a REST API endpoint that can be used to manage the contents. The Video Pipeline manager uses this API to create summaries and embeddings.
Benefits: DL Streamer pipeline server is a standard offering by Intel, which is optimized for media- and vision analytics-based inference tasks. See the DL Streamer pipeline server documentation for details.
Video Summarization pipeline manager microservice:
What it is: This microservice orchestrates the pipeline per user configuration. The pipeline manager uses a message bus to coordinate across different microservices and also provides performance-motivated capabilities like batching and parallel handling of multiple operations.
How it is used: The UI front-end uses a REST API endpoint to send user queries and trigger the summarization pipeline.
Benefits: The microservice provides a reference on how different microservices are orchestrated.
Video Summarization UI microservices:
What it is: The UI microservice allows you to interact with the sample application. You can configure the capabilities and input video details, and trigger the Video Summarization pipeline.
How it is used: To interact with this microservice, you will use the UI interface.
Benefits: You can treat this microservice as a reference implementation.
Dependent microservices: The pipeline uses dependent microservices to realize the Video Search and Video Summarization features. The dependent microservices are divided into inference microservices and data-handling microservices:
Inference microservices:
Multimodal Embedding - Creates vector embeddings for semantic search.
Audio Analyzer - Provides audio transcription capabilities.
VLM microservice - Generates captions for video content.
Data-handling microservices
VDMS-based data preparation - Handles vector database storage and retrieval.
Vector Retriever - Enables semantic search across the video collection.
See the respective documentation for details.
Extensibility#
The Video Search and Summarization mode is modular and allows you to:
Change inference microservices:
The default option is OpenVINO™ model server. You can use other model servers, for example, the Virtual Large Language Model (vLLM) with OpenVINO model server as backend, and the Text Generation Inference (TGI) toolkit to host Embedding and Vision-Language Models (VLMs), but Intel has not validated this method.
The compulsory requirement is OpenAI API compliance. Intel does not guarantee that other model servers will provide the same performance as the default options.
Load different embedding, VLM, and LLM models:
Use models from Hugging Face Hub that integrate with OpenVINO toolkit, or from vLLM model hub. The models are passed as parameters to the corresponding model servers.
You can swap embedding models to optimize for different types of content or search requirements.
Configure different capabilities on Video Search and Video Summarization pipelines:
In addition to available capabilities, you can enable new capabilities if they make search results and summaries more accurate.
You can configure the UI, pipeline manager, and required microservices easily for such extensions.
Customize vector database and search configurations:
You can integrate different vector databases, for example, VDMS and Milvus, based on performance and scalability requirements.
You can tune search parameters, similarity thresholds, and indexing strategies for an optimal search performance.
Deploy on diverse Intel target hardware and deployment scenarios:
Follow the system requirements guidelines on the options available for Video Search and Video Summarization workloads.