How it Works#
The stack ingests an RTSP stream, runs a DLStreamer pipeline that samples frames for VLM inference, and sends results to the dashboard.
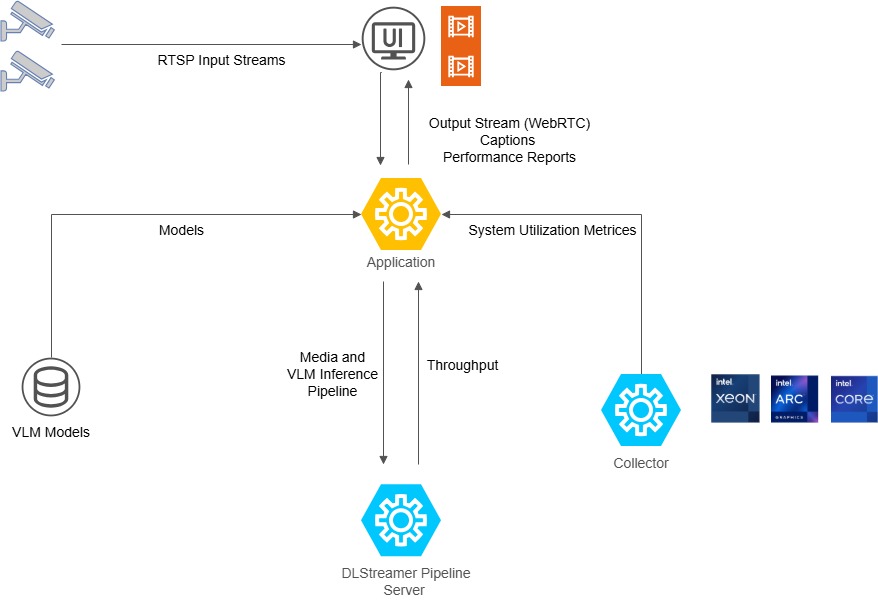
Data Flow#
RTSP Source → dlstreamer-pipeline-server
├─→ 1fps AI branch (GStreamer gvagenai) → MQTT Broker
└─→ 30fps preview → mediamtx (WebRTC) → Dashboard
↓
Dashboard collects metrics (CPU, GPU, RAM)
System Components#
dlstreamer-pipeline-server: Intel DLStreamer Pipeline Server processing RTSP sources with GStreamer pipelines and
gvagenaifor VLM inferencemediamtx: WebRTC/WHIP signaling server for video streaming
coturn: TURN server for NAT traversal in WebRTC connections
app: Python FastAPI backend serving REST APIs, SSE metadata streams, and WebSocket metrics
collector: Intel VIP-PET system metrics collector (CPU, GPU, memory, power)