Deploy Multiple Instances with Helm#
Prerequisites#
Ensure you meet the System Requirements for this application.
K8s installation on single or multi node must be done as pre-requisite to continue the following deployment. Note: The Kubernetes cluster is set up with
kubeadm,kubectlandkubeletpackages on single and multi nodes withv1.30.2. Refer to tutorials online to setup kubernetes cluster on the web with host OS as ubuntu 22.04 and/or ubuntu 24.04.For Helm installation, refer to Helm website
Setup the application#
Note: The following instructions assume Kubernetes is already running in the host system with Helm package manager installed.
Clone the edge-ai-suites repository and change into industrial-edge-insights-vision directory. The directory contains the utility scripts required in the instructions that follows.
git clone https://github.com/open-edge-platform/edge-ai-suites.git -b main cd edge-ai-suites/manufacturing-ai-suite/industrial-edge-insights-vision/
Note: These steps demonstrate launching two pallet-defect-detection instances and one weld-porosity instance. Modify the sample apps and instances as needed for your use case.
Create a
config.ymlfile to define your application instances and their unique port configurations. Add the following sample contents and save.Example:
pallet-defect-detection: pdd1: NGINX_HTTP_PORT: 30080 NGINX_HTTPS_PORT: 30443 COTURN_PORT: 30478 S3_STORAGE_PORT: 30800 pdd2: NGINX_HTTP_PORT: 30081 NGINX_HTTPS_PORT: 30444 COTURN_PORT: 30479 S3_STORAGE_PORT: 30801 weld-porosity: weld1: NGINX_HTTP_PORT: 30082 NGINX_HTTPS_PORT: 30445 COTURN_PORT: 30480 S3_STORAGE_PORT: 30802
Note: A sample configuration file
sample_config.ymlis provided to help users understand the multi-instance setup and get started. This configuration defines three example instances with identifiers:pdd1,pdd2, andweld1. The accompanying sample scripts utilize these identifiers to perform operations on individual application instances.Edit the below mentioned environment variables in all the
helm/values_<SAMPLE_APP>.yamlfiles:HOST_IP=<HOST_IP> # IP address of server where DL Streamer Pipeline Server is running. MINIO_ACCESS_KEY= # MinIO service & client access key e.g. intel1234 MINIO_SECRET_KEY= # MinIO service & client secret key e.g. intel1234 MTX_WEBRTCICESERVERS2_0_USERNAME=<username> # WebRTC credentials e.g. intel1234 MTX_WEBRTCICESERVERS2_0_PASSWORD=<password>
Note: For GPU/NPU based pipelines, set
privileged_access_required: truein thehelm/values_<SAMPLE_APP>.yamlfile to enable access to host hardware devices.Install pre-requisites for all instances
./setup.sh helmThis does the following:
Parses through the
config.ymlDownloads resources for each instance
Creates a folder helm/temp_apps/<SAMPLE_APP>/<INSTANCE_NAME> that contains configs folder, .env file, payload.json, Chart.yaml, pipeline-server-config.json and values.yaml.
Updates and adds the ports mentioned in
config.ymlto the respective values.yaml fileSets executable permissions for scripts
Deploy the application#
Install Helm charts#
Install the Helm chart for all instances.
./run.sh helm_installAfter installation, check the status of the running pods for each instance:
kubectl get pods -n <INSTANCE_NAME>
To view logs of a specific pod, replace
<pod_name>with the actual pod name from the output above:kubectl logs -n <INSTANCE_NAME> -f <pod_name>
Copy the resources such as video and model from local directory to the to the
dlstreamer-pipeline-serverpod to make them available for application while launching pipelines.# Below is an example for Pallet Defect Detection. Please adjust the source path of models and videos appropriately for other sample applications. POD_NAME=$(kubectl get pods -n <INSTANCE_NAME> -o jsonpath='{.items[*].metadata.name}' | tr ' ' '\n' | grep deployment-dlstreamer-pipeline-server | head -n 1) kubectl cp resources/pallet-defect-detection/videos/warehouse.avi $POD_NAME:/home/pipeline-server/resources/videos/ -c dlstreamer-pipeline-server -n <INSTANCE_NAME> kubectl cp resources/pallet-defect-detection/models/* $POD_NAME:/home/pipeline-server/resources/models/ -c dlstreamer-pipeline-server -n <INSTANCE_NAME>
Start AI pipelines#
Start pipeline for all instances#
Fetch the list of pipeline loaded available to launch for all instances
./sample_list.sh helmThis lists the pipeline loaded in DL Streamer Pipeline Server.
Output:
------------------------------------------- Status of: pdd1 (SAMPLE_APP: pallet-defect-detection) ------------------------------------------- Environment variables loaded from /home/intel/IRD/edge-ai-suites/manufacturing-ai-suite/industrial-edge-insights-vision/helm/temp_apps/pallet-defect-detection/pdd1/.env Running sample app: pallet-defect-detection Using Helm deployment - curl commands will use: <HOST_IP>:<NGINX_HTTPS_PORT> Checking status of dlstreamer-pipeline-server... Server reachable. HTTP Status Code: 200 Getting list of loaded pipelines... Loaded pipelines: [ { "description": "DL Streamer Pipeline Server pipeline", "name": "user_defined_pipelines", "parameters": { "properties": { "detection-properties": { "element": { "format": "element-properties", "name": "detection" } } ... ------------------------------------------- Status of: pdd2 (SAMPLE_APP: pallet-defect-detection) ------------------------------------------- Environment variables loaded from /home/intel/IRD/edge-ai-suites/manufacturing-ai-suite/industrial-edge-insights-vision/helm/temp_apps/pallet-defect-detection/pdd2/.env Running sample app: pallet-defect-detection Using Helm deployment - curl commands will use: <HOST_IP>:<NGINX_HTTPS_PORT> Checking status of dlstreamer-pipeline-server... Server reachable. HTTP Status Code: 200 Getting list of loaded pipelines... Loaded pipelines: [ { "description": "DL Streamer Pipeline Server pipeline", "name": "user_defined_pipelines", "parameters": { "properties": { "detection-properties": { "element": { "format": "element-properties", "name": "detection" } } ... ------------------------------------------- Status of: weld1 (SAMPLE_APP: weld-porosity) ------------------------------------------- Environment variables loaded from /home/intel/IRD/edge-ai-suites/manufacturing-ai-suite/industrial-edge-insights-vision/helm/temp_apps/weld-porosity/weld1/.env Running sample app: weld-porosity Using Helm deployment - curl commands will use: <HOST_IP>:<NGINX_HTTPS_PORT> Checking status of dlstreamer-pipeline-server... Server reachable. HTTP Status Code: 200 Getting list of loaded pipelines... Loaded pipelines: [ { "description": "DL Streamer Pipeline Server pipeline", "name": "user_defined_pipelines", "parameters": { "properties": { "classification-properties": { "element": { "format": "element-properties", "name": "classification" } } ... ]Start the pipeline for all instances in the
config.ymlfile./sample_start.sh helmExample Output:
No pipeline specified. Starting the first pipeline. ------------------------------------------ Processing instance: pdd1 from SAMPLE_APP: pallet-defect-detection ------------------------------------------ Environment variables loaded from /home/intel/IRD/edge-ai-suites/manufacturing-ai-suite/industrial-edge-insights-vision/helm/temp_apps/pallet-defect-detection/pdd1/.env Running sample app: pallet-defect-detection Using Helm deployment - curl commands will use: <HOST_IP>:<NGINX_HTTPS_PORT> Checking status of dlstreamer-pipeline-server... Server reachable. HTTP Status Code: 200 Loading payload from /home/intel/IRD/edge-ai-suites/manufacturing-ai-suite/industrial-edge-insights-vision/helm/temp_apps/pallet-defect-detection/pdd1/payload.json Payload loaded successfully. Starting first pipeline: pallet_defect_detection Launching pipeline: pallet_defect_detection Extracting payload for pipeline: pallet_defect_detection Found 1 payload(s) for pipeline: pallet_defect_detection Payload for pipeline 'pallet_defect_detection' Response: "b34dc150062e11f1863a15371702ae06" ------------------------------------------ Processing instance: pdd2 from SAMPLE_APP: pallet-defect-detection ------------------------------------------ Environment variables loaded from /home/intel/IRD/edge-ai-suites/manufacturing-ai-suite/industrial-edge-insights-vision/helm/temp_apps/pallet-defect-detection/pdd2/.env Running sample app: pallet-defect-detection Using Helm deployment - curl commands will use: <HOST_IP>:<NGINX_HTTPS_PORT> Checking status of dlstreamer-pipeline-server... Server reachable. HTTP Status Code: 200 Loading payload from /home/intel/IRD/edge-ai-suites/manufacturing-ai-suite/industrial-edge-insights-vision/helm/temp_apps/pallet-defect-detection/pdd2/payload.json Payload loaded successfully. Starting first pipeline: pallet_defect_detection Launching pipeline: pallet_defect_detection Extracting payload for pipeline: pallet_defect_detection Found 1 payload(s) for pipeline: pallet_defect_detection Payload for pipeline 'pallet_defect_detection' Response: "b35b2a20062e11f1b059efacc0acb924" ------------------------------------------ Processing instance: weld1 from SAMPLE_APP: weld-porosity ------------------------------------------ Environment variables loaded from /home/intel/IRD/edge-ai-suites/manufacturing-ai-suite/industrial-edge-insights-vision/helm/temp_apps/weld-porosity/weld1/.env Running sample app: weld-porosity Using Helm deployment - curl commands will use: 1<HOST_IP>:<NGINX_HTTPS_PORT> Checking status of dlstreamer-pipeline-server... Server reachable. HTTP Status Code: 200 Loading payload from /home/intel/IRD/edge-ai-suites/manufacturing-ai-suite/industrial-edge-insights-vision/helm/temp_apps/weld-porosity/weld1/payload.json Payload loaded successfully. Starting first pipeline: weld_porosity_classification Launching pipeline: weld_porosity_classification Extracting payload for pipeline: weld_porosity_classification Found 1 payload(s) for pipeline: weld_porosity_classification Payload for pipeline 'weld_porosity_classification' Response: "b366127e062e11f19d9a75f141417eac"
Access the WebRTC stream
The inference stream can be viewed on WebRTC, in a browser, at the following url depending on the SAMPLE_APP:
Note: The
NGINX_HTTPS_PORTis different for each instance of the sample app. For example, for the sample config mentioned previously, the instance pdd1 has nginx port set to 30443, pdd2 set to 30444 & weld1 set to 30445.https://<HOST_IP>:<NGINX_HTTPS_PORT>/mediamtx/pdd/ # Pallet Defect Detection https://<HOST_IP>:<NGINX_HTTPS_PORT>/mediamtx/anomaly/ # PCB Anomaly Detection https://<HOST_IP>:<NGINX_HTTPS_PORT>/mediamtx/weld/ # Weld Porosity https://<HOST_IP>:<NGINX_HTTPS_PORT>/mediamtx/worker_safety/ # Worker Safety Gear detection
Start pipeline for a particular instance only#
Fetch the list of pipeline for <INSTANCE_NAME>:
./sample_list.sh helm -i <INSTANCE_NAME>
Example Output:
Instance name set to: pdd1 Found SAMPLE_APP: pallet-defect-detection for INSTANCE_NAME: pdd1 Environment variables loaded from /home/intel/IRD/edge-ai-suites/manufacturing-ai-suite/industrial-edge-insights-vision/helm/temp_apps/pallet-defect-detection/pdd1/.env Running sample app: pallet-defect-detection Using default deployment - curl commands will use: <HOST_IP>:<NGINX_HTTPS_PORT> Checking status of dlstreamer-pipeline-server... Server reachable. HTTP Status Code: 200 Getting list of loaded pipelines... Loaded pipelines: [ { "description": "DL Streamer Pipeline Server pipeline", "name": "user_defined_pipelines", "parameters": { "properties": { "detection-properties": { "element": { "format": "element-properties", "name": "detection" } } ... ]Start the pipeline for <INSTANCE_NAME>:
./sample_start.sh helm -i <INSTANCE_NAME> -p <PIPELINE_NAME>
Output:
Instance name set to: pdd2 Starting specified pipeline(s)... Found SAMPLE_APP: pallet-defect-detection for INSTANCE_NAME: pdd2 Environment variables loaded from /home/intel/IRD/edge-ai-suites/manufacturing-ai-suite/industrial-edge-insights-vision/helm/temp_apps/pallet-defect-detection/pdd2/.env Running sample app: pallet-defect-detection Using Helm deployment - curl commands will use: <HOST_IP>:<NGINX_HTTPS_PORT> Checking status of dlstreamer-pipeline-server... Server reachable. HTTP Status Code: 200 Loading payload from /home/intel/IRD/edge-ai-suites/manufacturing-ai-suite/industrial-edge-insights-vision/helm/temp_apps/pallet-defect-detection/pdd2/payload.json Payload loaded successfully. Starting pipeline: pallet_defect_detection Launching pipeline: pallet_defect_detection Extracting payload for pipeline: pallet_defect_detection Found 1 payload(s) for pipeline: pallet_defect_detection Payload for pipeline 'pallet_defect_detection' Response: "f3a34cd5062f11f1ab8defacc0acb924"
Acess WebRTC stream:
Open a browser and navigate to
https://<HOST_IP>:<NGINX_HTTPS_PORT>/mediamtx/<peer-id of SAMPLE_APP>/
Start pipeline for a particular instance from a custom payload.json#
Fetch the list of pipeline for <INSTANCE_NAME>:
./sample_list.sh helm -i <INSTANCE_NAME>
Example Output:
Environment variables loaded from .env Running sample app: pallet-defect-detection Checking status of dlstreamer-pipeline-server... Server reachable. HTTP Status Code: 200 Loaded pipelines: [ ... { "description": "DL Streamer Pipeline Server pipeline", "name": "user_defined_pipelines", "version": "pallet_defect_detection" } ... ]Start the pipeline for <INSTANCE_NAME> where pipeline is loaded from
: ./sample_start.sh helm -i <INSTANCE_NAME> --payload <file> -p <PIPELINE_NAME>
Output:
Instance name set to: pdd1 Custom payload file set to: custom_payload.json Starting specified pipeline(s)... Found SAMPLE_APP: pallet-defect-detection for INSTANCE_NAME: pdd1 Environment variables loaded from /home/intel/IRD/edge-ai-suites/manufacturing-ai-suite/industrial-edge-insights-vision/helm/temp_apps/pallet-defect-detection/pdd1/.env Running sample app: pallet-defect-detection Using Helm deployment - curl commands will use: <HOST_IP>:<NGINX_HTTPS_PORT> Checking status of dlstreamer-pipeline-server... Server reachable. HTTP Status Code: 200 Loading payload from custom_payload.json Payload loaded successfully. Starting pipeline: pallet_defect_detection_gpu Launching pipeline: pallet_defect_detection_gpu Extracting payload for pipeline: pallet_defect_detection_gpu Found 1 payload(s) for pipeline: pallet_defect_detection_gpu Payload for pipeline 'pallet_defect_detection_gpu'. Response: "3bd097ec065b11f1a30d3101230a4967"
Access WebRTC stream:
Open a browser and navigate to:
https://<HOST_IP>:<NGINX_HTTPS_PORT>/mediamtx/<peer-id of SAMPLE_APP>/
Monitor Applications#
Check Pipeline Status#
Get status of pipeline instance(s) of all instances.
./sample_status.sh helmThis command lists status of pipeline instances launched during the lifetime of sample application of all instances in the config file
Output:
No arguments provided. Fetching status for all pipeline instances. Config file found. Fetching status for all instances defined in /home/intel/IRD/edge-ai-suites/manufacturing-ai-suite/industrial-edge-insights-vision/config.yml Processing instance: pdd1 from sample app: pallet-defect-detection Environment variables loaded from /home/intel/IRD/edge-ai-suites/manufacturing-ai-suite/industrial-edge-insights-vision/helm/temp_apps/pallet-defect-detection/pdd1/.env Running sample app: pallet-defect-detection Using Helm deployment - curl commands will use: <HOST_IP>:<NGINX_HTTPS_PORT> [ { "avg_fps": 30.003179236553294, "elapsed_time": 97.189706325531, "id": "b34dc150062e11f1863a15371702ae06", "message": "", "start_time": 1770693307.7875352, "state": "COMPLETED" }, { "avg_fps": 30.1419409008953, "elapsed_time": 5.706332683563232, "id": "2b51cf36063111f1b19b15371702ae06", "message": "", "start_time": 1770694367.6247275, "state": "RUNNING" } ] Processing instance: pdd2 from sample app: pallet-defect-detection Environment variables loaded from /home/intel/IRD/edge-ai-suites/manufacturing-ai-suite/industrial-edge-insights-vision/helm/temp_apps/pallet-defect-detection/pdd2/.env Running sample app: pallet-defect-detection Using Helm deployment - curl commands will use: <HOST_IP>:<NGINX_HTTPS_PORT> [ { "avg_fps": 30.00630534767508, "elapsed_time": 97.17957949638367, "id": "b35b2a20062e11f1b059efacc0acb924", "message": "", "start_time": 1770693308.1801755, "state": "COMPLETED" }, { "avg_fps": 30.075114986748083, "elapsed_time": 5.586012363433838, "id": "2b632863063111f18b4cefacc0acb924", "message": "", "start_time": 1770694367.766532, "state": "RUNNING" } ] Processing instance: weld1 from sample app: weld-porosity Environment variables loaded from /home/intel/IRD/edge-ai-suites/manufacturing-ai-suite/industrial-edge-insights-vision/helm/temp_apps/weld-porosity/weld1/.env Running sample app: weld-porosity Using Helm deployment - curl commands will use: <HOST_IP>:<NGINX_HTTPS_PORT> [ { "avg_fps": 30.004351657011913, "elapsed_time": 22.463412046432495, "id": "b366127e062e11f19d9a75f141417eac", "message": "", "start_time": 1770693307.6337888, "state": "COMPLETED" }, { "avg_fps": 30.20726493152364, "elapsed_time": 5.462261199951172, "id": "2b71f4a2063111f1946d75f141417eac", "message": "", "start_time": 1770694367.907302, "state": "RUNNING" } ]Check status of only a particular instance:
./sample_status.sh helm -i <INSTANCE_NAME>
Check status of a particular instance_id of an instance
./sample_status.sh helm -i <INSTANCE_NAME> --id <INSTANCE_ID>
Stop Applications#
Stop Pipeline Instances#
Stop all pipelines of all instances:
./sample_stop.sh helmOutput
No pipelines specified. Stopping all pipeline instances ------------------------------------------- Processing instance: pdd1 (SAMPLE_APP: pallet-defect-detection) ------------------------------------------- Environment variables loaded from /home/intel/IRD/edge-ai-suites/manufacturing-ai-suite/industrial-edge-insights-vision/helm/temp_apps/pallet-defect-detection/pdd1/.env Running sample app: pallet-defect-detection Using Helm deployment - curl commands will use: <HOST_IP>:<NGINX_HTTPS_PORT> Checking status of dlstreamer-pipeline-server... Server reachable. HTTP Status Code: 200 Instance list fetched successfully. HTTP Status Code: 200 Found 1 running pipeline instances. Stopping pipeline instance with ID: 88065593063211f1a83815371702ae06 Pipeline instance with ID '88065593063211f1a83815371702ae06' stopped successfully. Response: { "avg_fps": 30.02882915265665, "elapsed_time": 8.391932249069214, "id": "88065593063211f1a83815371702ae06", "message": "", "start_time": 1770694952.6537187, "state": "RUNNING" } ------------------------------------------- Processing instance: pdd2 (SAMPLE_APP: pallet-defect-detection) ------------------------------------------- Environment variables loaded from /home/intel/IRD/edge-ai-suites/manufacturing-ai-suite/industrial-edge-insights-vision/helm/temp_apps/pallet-defect-detection/pdd2/.env Running sample app: pallet-defect-detection Using Helm deployment - curl commands will use: <HOST_IP>:<NGINX_HTTPS_PORT> Checking status of dlstreamer-pipeline-server... Server reachable. HTTP Status Code: 200 Instance list fetched successfully. HTTP Status Code: 200 Found 1 running pipeline instances. Stopping pipeline instance with ID: 881ff32a063211f1b67defacc0acb924 Pipeline instance with ID '881ff32a063211f1b67defacc0acb924' stopped successfully. Response: { "avg_fps": 30.069598458700824, "elapsed_time": 8.380553007125854, "id": "881ff32a063211f1b67defacc0acb924", "message": "", "start_time": 1770694952.8342986, "state": "RUNNING" } ------------------------------------------- Processing instance: weld1 (SAMPLE_APP: weld-porosity) ------------------------------------------- Environment variables loaded from /home/intel/IRD/edge-ai-suites/manufacturing-ai-suite/industrial-edge-insights-vision/helm/temp_apps/weld-porosity/weld1/.env Running sample app: weld-porosity Using Helm deployment - curl commands will use: <HOST_IP>:<NGINX_HTTPS_PORT> Checking status of dlstreamer-pipeline-server... Server reachable. HTTP Status Code: 200 Instance list fetched successfully. HTTP Status Code: 200 Found 1 running pipeline instances. Stopping pipeline instance with ID: 88318dd1063211f1bd9675f141417eac Pipeline instance with ID '88318dd1063211f1bd9675f141417eac' stopped successfully. Response: { "avg_fps": 30.144217405495226, "elapsed_time": 8.32663083076477, "id": "88318dd1063211f1bd9675f141417eac", "message": "", "start_time": 1770694953.002784, "state": "RUNNING" }Stop pipelines of given instance:
./sample_stop.sh helm -i <INSTANCE_NAME>
Output:
Found SAMPLE_APP: pallet-defect-detection for INSTANCE_NAME: pdd1 Environment variables loaded from /home/intel/IRD/edge-ai-suites/manufacturing-ai-suite/industrial-edge-insights-vision/helm/temp_apps/pallet-defect-detection/pdd1/.env Running sample app: pallet-defect-detection Using Helm deployment - curl commands will use: <HOST_IP>:<NGINX_HTTPS_PORT> Checking status of dlstreamer-pipeline-server... Server reachable. HTTP Status Code: 200 Instance list fetched successfully. HTTP Status Code: 200 Found 1 running pipeline instances. Stopping pipeline instance with ID: f49ee13b063211f18ae815371702ae06 Pipeline instance with ID 'f49ee13b063211f18ae815371702ae06' stopped successfully. Response: { "avg_fps": 30.113055800460913, "elapsed_time": 9.397908210754395, "id": "f49ee13b063211f18ae815371702ae06", "message": "", "start_time": 1770695134.8435106, "state": "RUNNING" }Stop pipelines of an instance with a given instance_id:
./sample_stop.sh helm -i <INSTANCE_NAME> --id <INSTANCE_ID>
Output:
Found SAMPLE_APP: pallet-defect-detection for INSTANCE_NAME: pdd1 Environment variables loaded from /home/intel/IRD/edge-ai-suites/manufacturing-ai-suite/industrial-edge-insights-vision/helm/temp_apps/pallet-defect-detection/pdd1/.env Running sample app: pallet-defect-detection Using Helm deployment - curl commands will use: <HOST_IP>:<NGINX_HTTPS_PORT> Checking status of dlstreamer-pipeline-server... Server reachable. HTTP Status Code: 200 Stopping pipeline instance with ID: 4562a97f063311f19f4d15371702ae06 Pipeline instance with ID '4562a97f063311f19f4d15371702ae06' stopped successfully. Response: { "avg_fps": 30.059924104470113, "elapsed_time": 15.868299961090088, "id": "4562a97f063311f19f4d15371702ae06", "message": "", "start_time": 1770695270.3738744, "state": "RUNNING" }
Uninstall Helm Charts#
./run.sh helm_uninstall
Once application has been stopped, remove or rename the config.yml file if you do not wish to relaunch these multiple apps next time.
Storing frames to S3 storage#
Applications can take advantage of S3 publish feature from DL Streamer Pipeline Server and use it to save frames to an S3 compatible storage.
Run all the steps mentioned in above section to setup the application.
Install the Helm chart.
./run.sh helm_installCopy the resources such as video and model from local directory to the
dlstreamer-pipeline-serverpod to make them available for application while launching pipelines.# Below is an example for Pallet Defect Detection. Please adjust the source path of models and videos appropriately for other sample applications. POD_NAME=$(kubectl get pods -n <INSTANCE_NAME> -o jsonpath='{.items[*].metadata.name}' | tr ' ' '\n' | grep deployment-dlstreamer-pipeline-server | head -n 1) kubectl cp resources/pallet-defect-detection/videos/warehouse.avi $POD_NAME:/home/pipeline-server/resources/videos/ -c dlstreamer-pipeline-server -n <INSTANCE_NAME> kubectl cp resources/pallet-defect-detection/models/* $POD_NAME:/home/pipeline-server/resources/models/ -c dlstreamer-pipeline-server -n <INSTANCE_NAME>
Install the package
boto3in your python environment if not installed.It is recommended to create a virtual environment and install it there. You can run the following commands to add the necessary dependencies as well as create and activate the environment.
sudo apt update && \ sudo apt install -y python3 python3-pip python3-venv
python3 -m venv venv && \ source venv/bin/activate
Once the environment is ready, install
boto3with the following commandpip3 install --upgrade pip && \ pip3 install boto3==1.36.17
Note: DL Streamer Pipeline Server expects the bucket to be already present in the database. The next step will help you create one.
Create a S3 bucket using the following script.
Update the
HOST_IPandS3_STORAGE_PORTmentioned inconfig.ymlfor each instance and credentials with that of the running MinIO server. Name the file ascreate_bucket_<INSTANCE_NAME>.py.import boto3 url = "http://<HOST_IP>:<S3_STORAGE_PORT>" user = "<value of MINIO_ACCESS_KEY used in helm/temp_apps/SAMPLE_APP/INSTANCE_NAME/values.yaml>" password = "<value of MINIO_SECRET_KEY used in helm/temp_apps/SAMPLE_APP/INSTANCE_NAME/values.yaml>" bucket_name = "ecgdemo" client= boto3.client( "s3", endpoint_url=url, aws_access_key_id=user, aws_secret_access_key=password ) client.create_bucket(Bucket=bucket_name) buckets = client.list_buckets() print("Buckets:", [b["Name"] for b in buckets.get("Buckets", [])])
Run the above script to create the bucket.
python3 create_bucket_<INSTANCE_NAME>.pyStart the pipeline with the following cURL command with
<HOST_IP>set to system IP and the<NGINX_HTTPS_PORT>mentioned in theconfig.ymlfor each instance. Ensure to give the correct path to the model as seen below. This example starts an AI pipeline for pallet_defect_detection. Please adjust the source path of models and videos appropriately for other sample applications.curl -k https://<HOST_IP>:<NGINX_HTTPS_PORT>/api/pipelines/user_defined_pipelines/pallet_defect_detection_s3write -X POST -H 'Content-Type: application/json' -d '{ "source": { "uri": "file:///home/pipeline-server/resources/videos/warehouse.avi", "type": "uri" }, "destination": { "frame": { "type": "webrtc", "peer-id": "pdds3" } }, "parameters": { "detection-properties": { "model": "/home/pipeline-server/resources/models/pallet-defect-detection/deployment/Detection/model/model.xml", "device": "CPU" } } }'
Go to MinIO console on
https://<HOST_IP>:<NGINX_HTTPS_PORT>/minio/and login withMINIO_ACCESS_KEYandMINIO_SECRET_KEYprovided inhelm/temp_apps/SAMPLE_APP/INSTANCE_NAME/values.yamlfile. After logging into console, you can go toecgdemobucket and check the frames stored.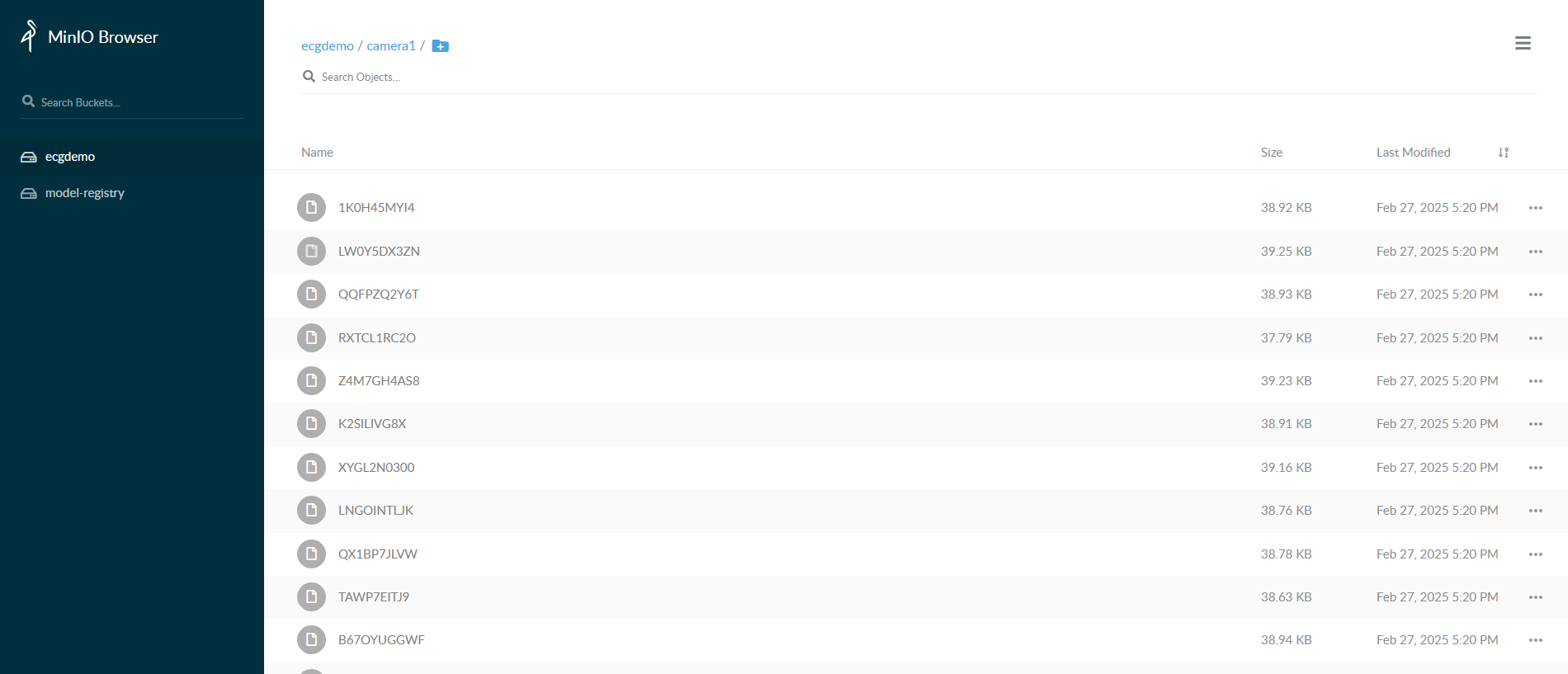
Uninstall the Helm chart.
./run.sh helm_uninstallOnce application has been stopped, remove or rename the
config.ymlfile if you do not wish to relaunch these multiple apps next time.
MLOps using Model Download#
Run all the steps mentioned in above section to setup the application.
Install the Helm chart
./run.sh helm_installCopy the resources such as video and model from local directory to the
dlstreamer-pipeline-serverpod to make them available for application while launching pipelines.# Below is an example for Pallet Defect Detection. Please adjust the source path of models and videos appropriately for other sample applications. POD_NAME=$(kubectl get pods -n <INSTANCE_NAME> -o jsonpath='{.items[*].metadata.name}' | tr ' ' '\n' | grep deployment-dlstreamer-pipeline-server | head -n 1) kubectl cp resources/pallet-defect-detection/videos/warehouse.avi $POD_NAME:/home/pipeline-server/resources/videos/ -c dlstreamer-pipeline-server -n <INSTANCE_NAME> kubectl cp resources/pallet-defect-detection/models/* $POD_NAME:/home/pipeline-server/resources/models/ -c dlstreamer-pipeline-server -n <INSTANCE_NAME>
Modify the payload in
helm/temp_apps/<SAMPLE_APP>/<INSTANCE_NAME>/payload.jsonto launch an instance for the mlops pipeline.Below is an example for pallet-defect-detection. Please modify the payload for other sample applications.
[ { "pipeline": "pallet_defect_detection_mlops", "payload":{ "source": { "uri": "file:///home/pipeline-server/resources/videos/warehouse.avi", "type": "uri" }, "destination": { "frame": { "type": "webrtc", "peer-id": "pdd" } }, "parameters": { "detection-properties": { "model": "/home/pipeline-server/resources/models/pallet-defect-detection/deployment/Detection/model/model.xml", "device": "CPU" } } } } ]
Start the pipeline with the above payload.
Below is an example for starting an instance for pallet-defect-detection:
./sample_start.sh helm -i <INSTANCE_NAME> -p pallet_defect_detection_mlops
Note the instance-id.
Download and prepare the model. Below is an example for downloading and preparing model for pallet-defect-detection. Please modify MODEL_URL for the other sample applications.
Note: For sake of simplicity, we assume that the new model has already been downloaded by Model Download microservice. The following curl command is only a simulation that just downloads the model. In production, however, they will be downloaded by the Model Download service.
export MODEL_URL='https://github.com/open-edge-platform/edge-ai-resources/raw/06bb0d621cb14a1791672552a538beddddcc4066/models/INT8/pallet_defect_detection.zip' curl -L "$MODEL_URL" -o "$(basename $MODEL_URL)" unzip "$(basename $MODEL_URL)" -d new-model # downloaded model is now extracted to `new-model` directory.
Copy the new model to the
dlstreamer-pipeline-serverpod to make it available for application while launching pipeline.POD_NAME=$(kubectl get pods -n <INSTANCE_NAME> -o jsonpath='{.items[*].metadata.name}' | tr ' ' '\n' | grep deployment-dlstreamer-pipeline-server | head -n 1) kubectl cp new-model $POD_NAME:/home/pipeline-server/resources/models/ -c dlstreamer-pipeline-server -n <INSTANCE_NAME>
Note: If there are multiple
sample_appsinconfig.yml, repeat steps 6 and 7 for each sample app and instance.Stop the existing pipeline before restarting it with a new model. Use the instance-id generated from step 5.
curl -k --location -X DELETE https://<HOST_IP>:<NGINX_HTTPS_PORT>/api/pipelines/{instance_id}
Modify the payload in
helm/temp_apps/<SAMPLE_APP>/<INSTANCE_NAME>/payload.jsonto launch an instance for the mlops pipeline with this new model.Below is an example for pallet-defect-detection. Please modify the payload for other sample applications.
[ { "pipeline": "pallet_defect_detection_mlops", "payload":{ "source": { "uri": "file:///home/pipeline-server/resources/videos/warehouse.avi", "type": "uri" }, "destination": { "frame": { "type": "webrtc", "peer-id": "pdd" } }, "parameters": { "detection-properties": { "model": "/home/pipeline-server/resources/models/new-model/deployment/Detection/model/model.xml", "device": "CPU" } } } } ]
View the WebRTC streaming on
https://<HOST_IP>:<NGINX_HTTPS_PORT>/mediamtx/<peer-str-id>/by replacing<peer-str-id>with the value used in the original cURL command to start the pipeline.