How to Deploy with Helm#
This section provides step-by-step instructions for deploying the Smart Parking sample application using Helm.
The estimated time to complete this procedure is 30 minutes.
Get Started#
Complete this section to confirm that your setup is working correctly and try out workflows in the sample application.
Prerequisites#
K8s installation on single or multi node must be done as pre-requisite to continue the following deployment. Note: The kubernetes cluster is set up with
kubeadm,kubectlandkubeletpackages on single and multi nodes withv1.30.2. Refer to tutorials such as https://adamtheautomator.com/installing-kubernetes-on-ubuntu and many other online tutorials to setup kubernetes cluster on the web with host OS as ubuntu 22.04.For helm installation, refer to helm website
Note If Ubuntu Desktop is not installed on the target system, follow the instructions from Ubuntu to install Ubuntu desktop.The target system refers to the system where you are installing the application.
Step 1: Download the Helm chart#
Follow this procedure on the target system to download the package.
Note: Skip this step if you have already followed the steps as part of the Get Started guide.
Before you can deploy with Helm, you must clone the repository and download the helm chart:
# Clone the repository
git clone https://github.com/open-edge-platform/edge-ai-suites.git
# Navigate to the Metro AI Suite directory
cd edge-ai-suites/metro-ai-suite/metro-vision-ai-app-recipe/
Step 2: Configure and update the environment variables#
Update the below fields in
values.yamlfile in the Helm chart# Edit the values.yml file to add proxy configuration nano ./smart-parking/helm-chart/values.yaml
HOST_IP: # replace localhost with system IP example: HOST_IP: 10.100.100.100 http_proxy: # example: http_proxy: http://proxy.example.com:891 https_proxy: # example: http_proxy: http://proxy.example.com:891 webrtcturnserver: username: # example: username: myuser password: # example: password: mypassword
Step 3: Deploy the application and Run multiple AI pipelines#
Follow this procedure to run the sample application. In a typical deployment, multiple cameras deliver video streams that are connected to AI pipelines to improve the classification and recognition accuracy. The following demonstrates running multiple AI pipelines and visualization in the Grafana.
Deploy Helm chart
helm install smart-parking ./smart-parking/helm-chart -n sp --create-namespace
Verify all the pods and services are running:
kubectl get pods -n sp kubectl get svc -n sp
Start the application with the Client URL (cURL) command by replacing the <HOST_IP> with the Node IP. (Total 8 places)
#!/bin/bash
curl http://<HOST_IP>:30485/pipelines/user_defined_pipelines/yolov10_1_cpu -X POST -H 'Content-Type: application/json' -d '
{
"source": {
"uri": "file:///home/pipeline-server/videos/new_video_1.mp4",
"type": "uri"
},
"destination": {
"metadata": {
"type": "mqtt",
"topic": "object_detection_1",
"publish_frame":false
},
"frame": {
"type": "webrtc",
"peer-id": "object_detection_1"
}
},
"parameters": {
"detection-device": "CPU"
}
}'
curl http://<HOST_IP>:30485/pipelines/user_defined_pipelines/yolov10_1_cpu -X POST -H 'Content-Type: application/json' -d '
{
"source": {
"uri": "file:///home/pipeline-server/videos/new_video_2.mp4",
"type": "uri"
},
"destination": {
"metadata": {
"type": "mqtt",
"topic": "object_detection_2",
"publish_frame":false
},
"frame": {
"type": "webrtc",
"peer-id": "object_detection_2"
}
},
"parameters": {
"detection-device": "CPU"
}
}'
curl http://<HOST_IP>:30485/pipelines/user_defined_pipelines/yolov10_1_cpu -X POST -H 'Content-Type: application/json' -d '
{
"source": {
"uri": "file:///home/pipeline-server/videos/new_video_3.mp4",
"type": "uri"
},
"destination": {
"metadata": {
"type": "mqtt",
"topic": "object_detection_3",
"publish_frame":false
},
"frame": {
"type": "webrtc",
"peer-id": "object_detection_3"
}
},
"parameters": {
"detection-device": "CPU"
}
}'
curl http://<HOST_IP>:30485/pipelines/user_defined_pipelines/yolov10_1_cpu -X POST -H 'Content-Type: application/json' -d '
{
"source": {
"uri": "file:///home/pipeline-server/videos/new_video_4.mp4",
"type": "uri"
},
"destination": {
"metadata": {
"type": "mqtt",
"topic": "object_detection_4",
"publish_frame":false
},
"frame": {
"type": "webrtc",
"peer-id": "object_detection_4"
}
},
"parameters": {
"detection-device": "CPU"
}
}'
View the Grafana and WebRTC streaming on
http://<HOST_IP>:30480.Log in with the following credentials:
Username:
adminPassword:
admin
Check under the Dashboards section for the default dashboard named “Video Analytics Dashboard”.
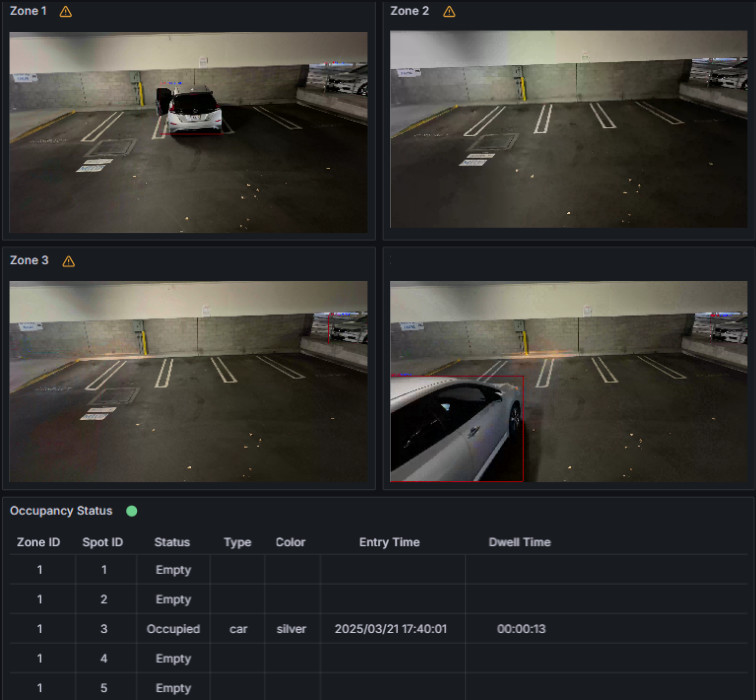
Figure 1: Grafana and WebRTC streaming
Step 4: End the demonstration#
Follow this procedure to stop the sample application and end this demonstration.
Stop the sample application with the following command that uninstalls the release smart-parking.
helm uninstall smart-parking -n sp
Confirm the pods are no longer running.
kubectl get pods -n sp
Summary#
In this guide, you installed and validated Smart Parking sample application. You also completed a demonstration where multiple pipelines run on a single system with near real-time classification.
Troubleshooting#
The following are options to help you resolve issues with the sample application.
Deploy with Intel GPU K8S Extension on Intel® Tiber™ Edge Platform#
If you’re deploying a GPU based pipeline (example: with VA-API elements like vapostproc, vah264dec etc., and/or with device=GPU in gvadetect in config.json) with Intel GPU k8s Extension on Intel® Tiber™ Edge Platform, ensure to set the following details in the file helm/values.yaml appropriately in order to utilize the underlying GPU.
gpu:
enabled: true
type: "gpu.intel.com/i915"
count: 1
Deploying without Intel GPU K8S Extension#
If you’re deploying a GPU based pipeline (example: with VA-API elements like vapostproc, vah264dec etc., and/or with device=GPU in gvadetect in config.json) without Intel GPU k8s Extension, ensure to set the below details in the file helm/values.yaml appropriately in order to utilize the underlying GPU.
privileged_access_required: true
Error Logs#
View the container logs using the following command:
kubectl logs -f <pod_name> -n sp