GraspNet - Baseline#
Robotic grasping is a fundamental challenge in robotics, requiring the generation of stable and feasible grasps for a wide variety of objects. Existing methods often struggle with generalization across diverse objects and lack large-scale datasets for training and evaluation. The GraspNet project introduced a GraspNet-1Billion Dataset and a baseline Grasp Generation Model:
GraspNet-1Billion Dataset:
A massive dataset containing 1 billion grasp poses for 88,000 object models.
Each object is associated with multiple grasp poses, annotated with stability labels and quality scores.
The dataset is designed to cover a wide range of object shapes, sizes, and materials, enabling robust training and evaluation of grasp generation models.
Grasp Generation Model:
A deep learning-based model that predicts 6-DoF grasp poses (position and orientation) for objects in a scene.
The model takes as input a point cloud representation of the scene and outputs a set of candidate grasps, ranked by their predicted stability and quality.
Grasp Representation: - Grasps are represented as 6-DoF poses of a robotic gripper, defined by:
A 3D position (where the gripper should be placed).
A 3D orientation (how the gripper should be aligned).
Each grasp is also associated with a quality score that indicates its stability and feasibility.
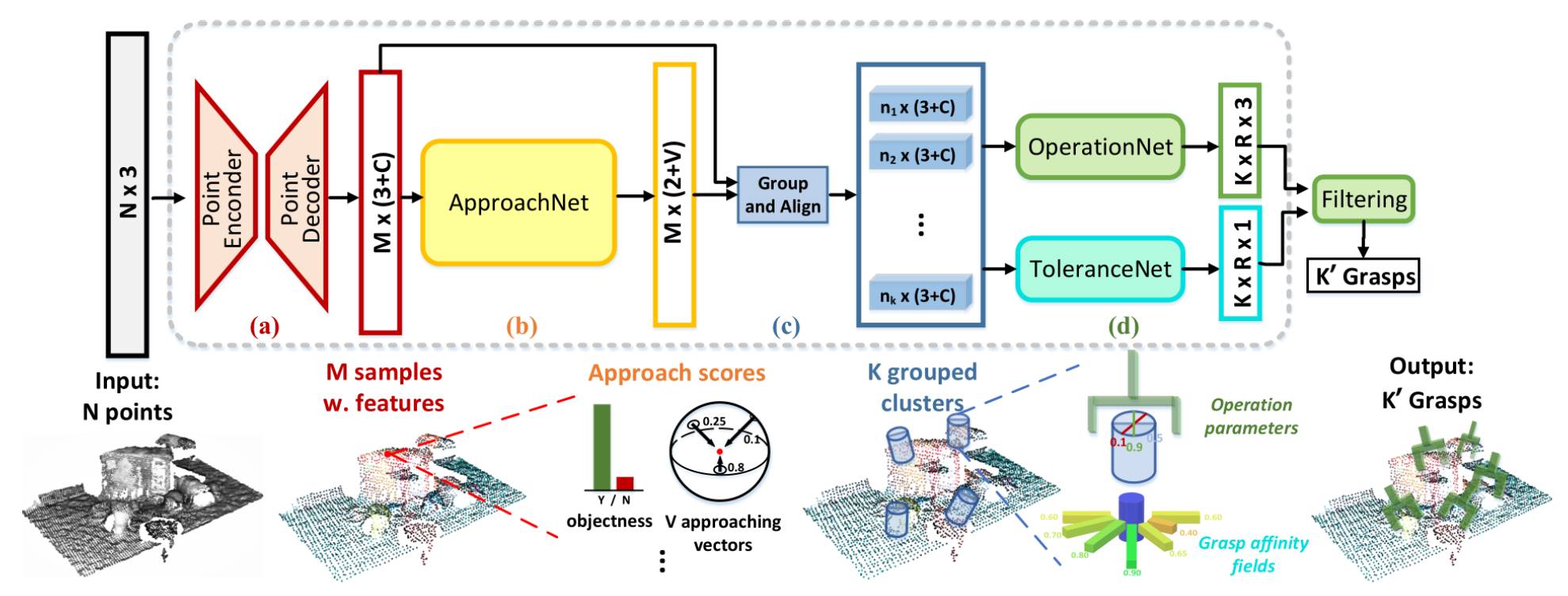
Model Architecture:
The grasp generation model consists of:
Point Cloud Encoder:
A neural network (e.g., PointNet or PointNet++) processes the input point cloud to extract features.
Grasp Proposal Network:
Generates candidate grasp poses based on the extracted features.
Grasp Evaluation Network:
Scores and ranks the candidate grasps based on their predicted stability and quality.
The model is trained end-to-end using the GraspNet-1Billion dataset.
More Information:
Homepage: https://graspnet.net/
Github link: graspnet/graspnet-baseline