Optimizing π0.5 Vision–Language–Action Robotic Model on Intel Core Ultra Series 3 Processor#
Asaad F Said, Radwan Ibrahim, Harshil Patel, Deepak S, Alex Turk, Amrutha Dhanakumar, Chon Ming Lee, Sergey Shumihin, Anand Bodas, Parual Datta, Deepa Suresh, Vladislav Sovrasov, Daniil Lyakhov, Daan Krol, Alfie Roddan, Samet Akcay, Ashutosh Kumar, Greeshma Pisharody
Abstract#
Vision–Language–Action (VLA) models unify perception, natural language understanding, and control in an end-to-end robotics framework. This enables generalization across tasks and environments with minimal task-specific customization compared with modular pipelines. Deploying VLA models at the edge is challenging as it requires high compute efficiency and substantial memory bandwidth for real-time inference. Intel® Core™ Ultra Series 3 (codenamed Panther Lake) addresses these requirements with a heterogeneous CPU–GPU–NPU architecture. It provides up to 180 TOPS of compute and up to 154 GB/s of memory bandwidth.
In this work, we evaluate the edge deployment of the π0.5 VLA model, selected for its exceptional reliability on manipulation tasks in unfamiliar environments. We optimize π0.5 for Panther Lake. We then benchmark its performance against leading embedded AI platforms. We show up to 2.6× higher performance per watt than NVIDIA Jetson AGX Orin (64 GB) and up to 1.3× over NVIDIA® Jetson Thor™. These results position Panther Lake as a strong platform for real-time VLA inference in edge robotics.
Demo#
Quick Start - Run π0.5 on Intel XPU:#
pip install physicalai-train
# config.yaml
model:
class_path: physicalai.policies.Pi05
init_args:
paligemma_variant: gemma_2b
action_expert_variant: gemma_300m
dtype: bfloat16
data:
class_path: physicalai.data.lerobot.LeRobotDataModule
init_args:
repo_id: "<repoid>"
# Train with config file
physicalai fit --config config.yaml
from physicalai.data import LeRobotDataModule
from physicalai.policies import Pi05
from physicalai.train import Trainer
datamodule = LeRobotDataModule(repo_id="<repoid>")
model = Pi05()
trainer = Trainer()
trainer.fit(model=model, datamodule=datamodule)
physicalai export \
--ckpt_path "<path>" \
--backend "openvino" \
--output_dir "pi05_ov"
from physicalai.policies import Pi05
policy = Pi05(pretrained_name_or_path="<path/or/repoid>")
policy.to_openvino(output_path="./pi05_ov")
# runtime.yaml
runtime:
class_path: physicalai.runtime.PolicyRuntime
init_args:
fps: 30
robot:
class_path: physicalai.robot.trossen.BimanualWidowXAI
init_args:
left:
class_path: physicalai.robot.trossen.WidowXAI
init_args:
ip: "192.168.1.10"
role: "follower"
right:
class_path: physicalai.robot.trossen.WidowXAI
init_args:
ip: "192.168.1.11"
role: "follower"
model:
class_path: physicalai.inference.InferenceModel
init_args:
export_dir: ./exports/pi05_ov
cameras:
wrist:
class_path: physicalai.capture.UVCCamera
init_args:
device: /dev/video0
width: 640
height: 480
overhead:
class_path: physicalai.capture.RealSenseCamera
init_args:
serial: "123456789"
execution:
class_path: physicalai.runtime.SyncExecution
init_args:
mode: chunk
# Run
physicalai run --config runtime.yaml --duration-s 60
from physicalai.runtime import PolicyRuntime, SyncExecution
from physicalai.inference import InferenceModel
from physicalai.capture import UVCCamera, RealSenseCamera
from physicalai.robot.trossen import WidowXAI, BimanualWidowXAI
left = WidowXAI(ip="192.168.1.10", role="follower")
right = WidowXAI(ip="192.168.1.11", role="follower")
robot = BimanualWidowXAI(left=left, right=right)
runtime = PolicyRuntime(
fps=30,
robot=robot,
model=InferenceModel.load("./pi05_ov", backend="openvino"),
cameras={
"wrist": UVCCamera(device="/dev/video0", width=640, height=480),
"overhead": RealSenseCamera(serial="123456789"),
},
execution=SyncExecution(mode="chunk"),
)
runtime.run(duration_s=60)
Methods#
We decompose π0.5 for heterogeneous execution across the Panther Lake compute hierarchy: the Vision Encoder (VE) and Language Model (LM) run on the iGPU, while the Action Expert (AE) runs on the NPU. The per-layer KV cache is the only cross-device handoff, carried via shared DDR with zero-copy USM-host tensors.
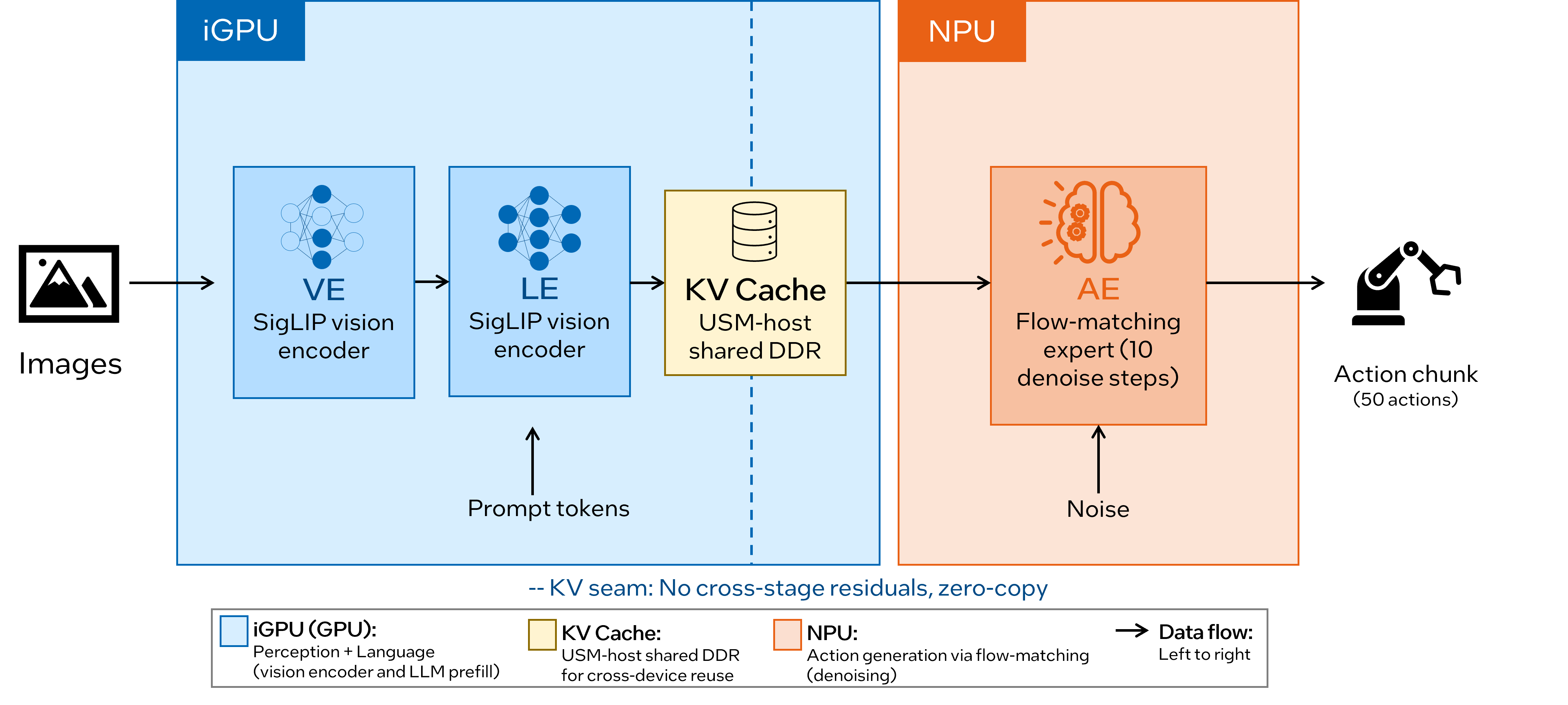 Figure 1. π0.5 decomposition for heterogeneous execution: VE and LM on the iGPU, AE on the NPU, with the per-layer KV cache as the only cross-device handoff in shared DDR.
Figure 1. π0.5 decomposition for heterogeneous execution: VE and LM on the iGPU, AE on the NPU, with the per-layer KV cache as the only cross-device handoff in shared DDR.
Results#
We benchmark π0.5 (DROID variant, 3 cameras × 224×224, 64-token language context, 10 denoising steps, BF16/FP16) across three edge platforms at both Max TDP and ISO-TDP (40 W).
Hardware Configurations#
Spec |
NVIDIA Jetson AGX Orin 64GB |
NVIDIA Jetson Thor T5000 |
Intel® Core™ Ultra Series 3 (X7 358H) |
|---|---|---|---|
TDP (W) |
15-60 |
40-130 |
15-65 |
CPU |
12-core Arm(R) Cortex(R)-A78AE |
14-core Arm(R) Neoverse-V3AE |
16-core (4P + 8E + 4LP-E) |
Memroy (GB) |
64 GB 256-bit LPDDR5 @204.8GB/s |
128GB 256-bit LPDDR5 @273GB/s |
32GB (2x16GB LPDDR5 8533 MT/s |
Storage (GB) |
64GB eMMC 5.1 |
1 TB NVMe SSD |
1 TB NVMe SSD |
Peak AI (INT8) |
275 TOPS (Sparse) |
1035 TOPS (Sparse) |
180 TOPS (Dense) |
GPU TOPS (INT8-Dense) |
85 |
517 |
122 |
Peak BW (GB/s) |
204 |
273 |
153 |
Capacity (GB) |
64 |
128 |
128 |
Operating System |
Ubuntu 22.04.5 LTS |
Ubuntu 24.04.3 LTS |
Ubuntu 24.04.4 LTS |
Kernel version |
5.15.148-tegra |
6.8.12-tegra |
6.17.0-14-generic |
Jetpack version |
6.2.1 |
7.0 |
N/A |
CUDA version |
12.6 |
13.0 |
N/A |
OpenCL Compute Runtime version |
N/A |
N/A |
26.01.36711.4 |
π0.5 Latency: PyTorch XPU vs CUDA#
Using stock PyTorch 2.12, Intel® Core™ Ultra Series 3 X7 358H processor at 40 W records 294 ms — within 2.4% of NVIDIA Jetson Thor at full power (287 ms), and 3.5× / 5.2× faster than NVIDIA Jetson AGX Orin at 60 W / 40 W respectively.
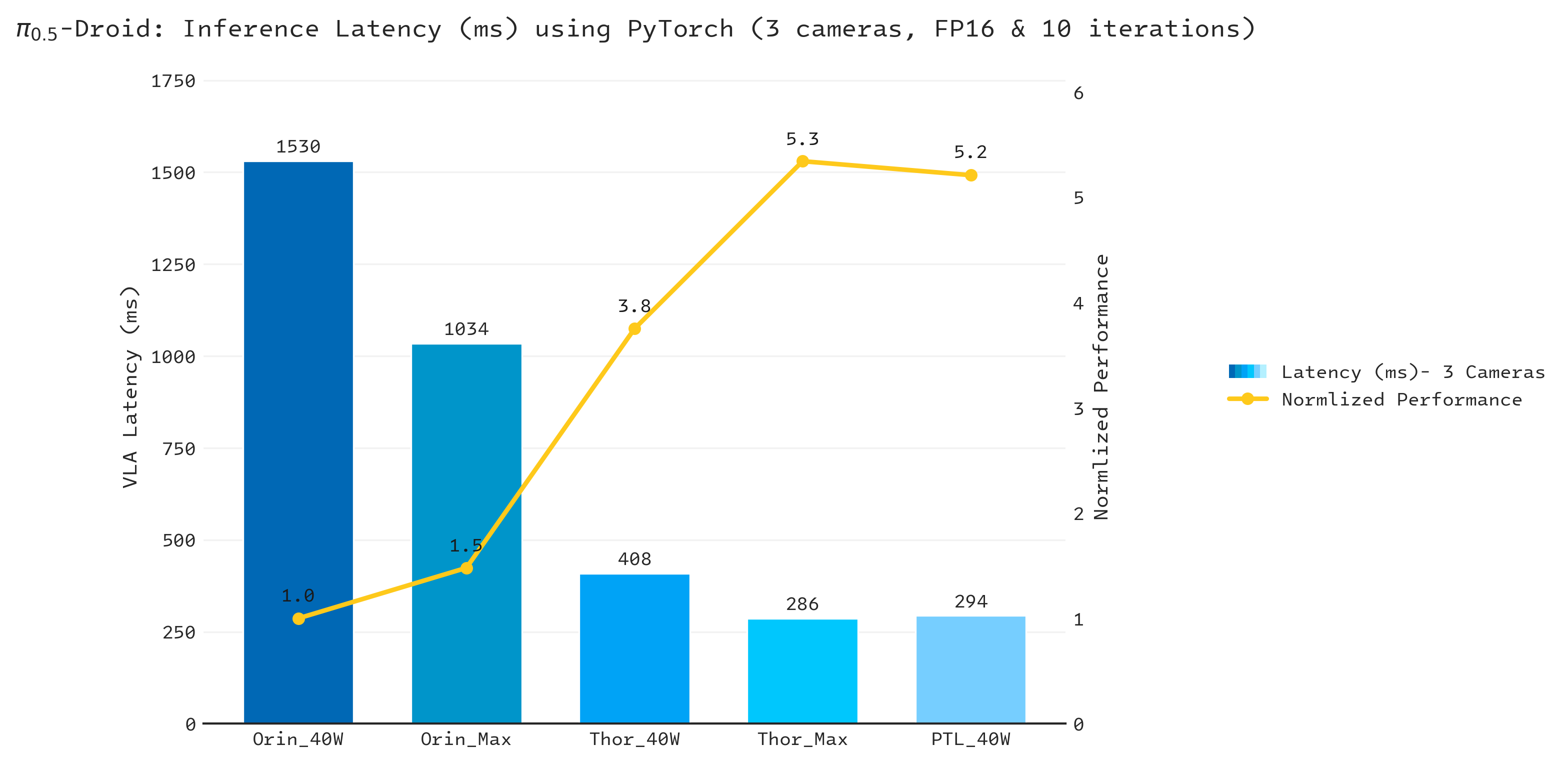 Figure 2. π0.5 model latency using PyTorch on Core Ultra X7 358H, Jetson AGX Orin, and Jetson Thor.
Figure 2. π0.5 model latency using PyTorch on Core Ultra X7 358H, Jetson AGX Orin, and Jetson Thor.
Optimised Performance at Max TDP#
With OpenVINO (Intel processors) and TensorRT (NVIDIA) at each platform’s maximum power envelope (65 W / 60 W / 130 W), Core Ultra X7 358H achieves up to 1.5× lower latency than AGX Orin and up to 1.3× better performance per watt than both NVIDIA platforms.
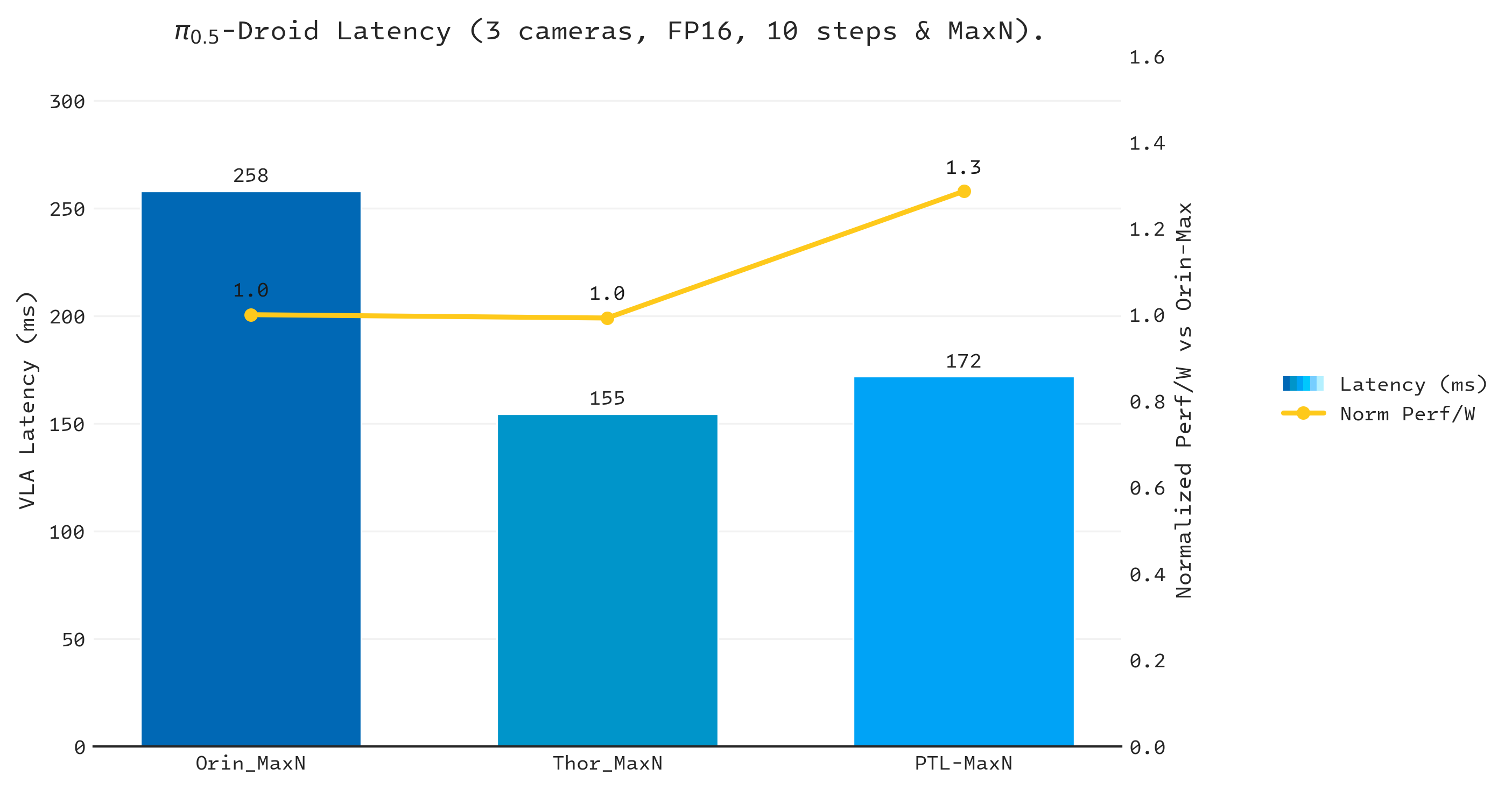 Figure 3. Competitive analysis of π0.5 on Core Ultra X7 358H, Jetson AGX Orin, and Jetson Thor at Max TDP.
Figure 3. Competitive analysis of π0.5 on Core Ultra X7 358H, Jetson AGX Orin, and Jetson Thor at Max TDP.
Optimised Performance at ISO-TDP (40 W)#
Capping all platforms at 40 W, Core Ultra X7 358H delivers the strongest results: up to 2.6× lower latency and 2.6× higher performance per watt versus Jetson AGX Orin, and 1.1× better latency and efficiency versus Jetson Thor.
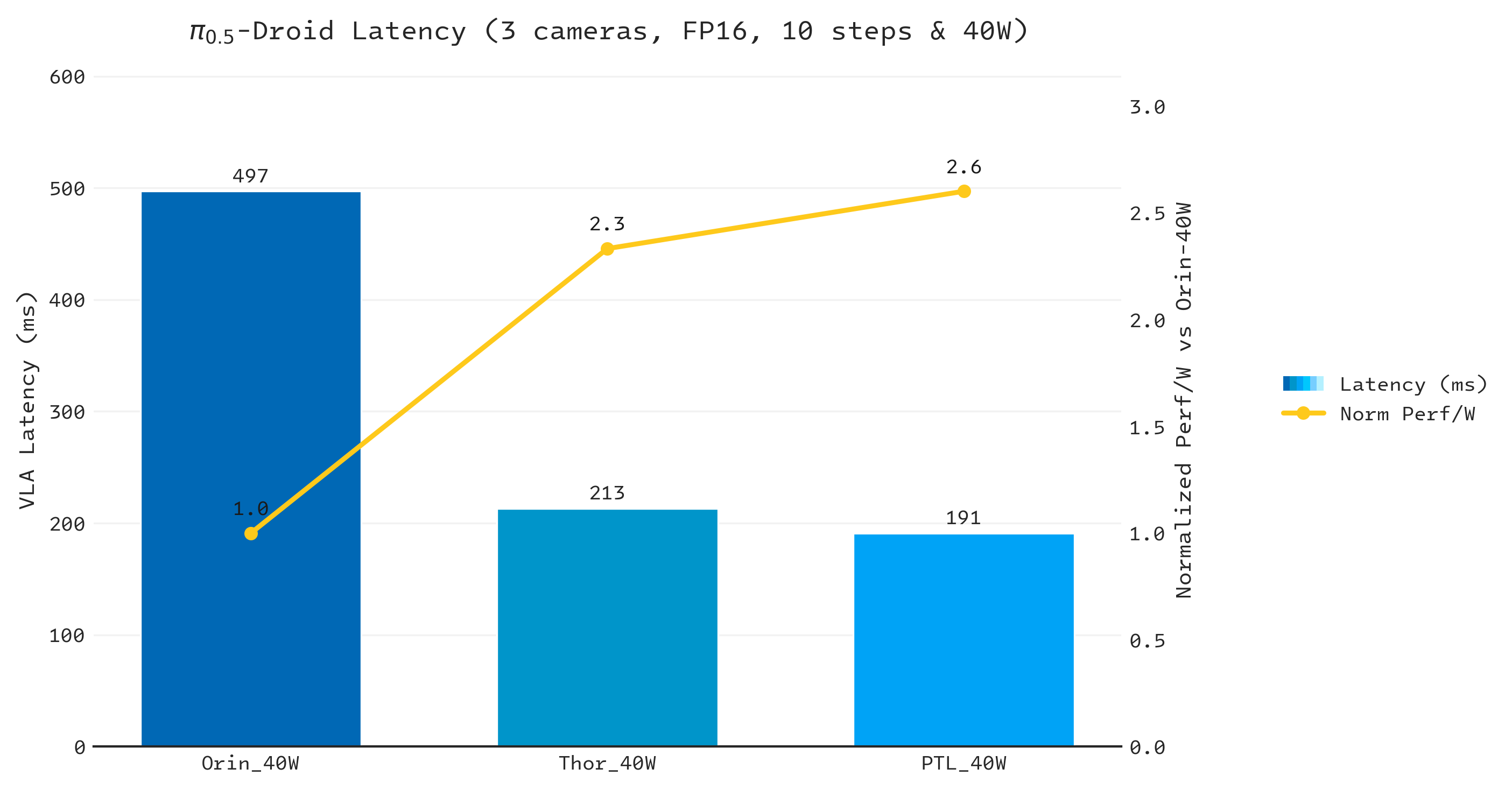 Figure 4. Competitive analysis of π0.5 on Core Ultra X7 358H, Jetson AGX Orin, and Jetson Thor at 40 W TDP.
Figure 4. Competitive analysis of π0.5 on Core Ultra X7 358H, Jetson AGX Orin, and Jetson Thor at 40 W TDP.