MLOps using Model Registry#
Applications for industrial vision can also be used to demonstrate MLOps workflow using Model Registry microservice. With this feature, during runtime, you can download a new model from the registry and restart the pipeline with the new model.
Contents#
Launch a pipeline in DLStreamer Pipeline Server#
Set up the sample application to start a pipeline. A pipeline named
worker_safety_gear_detection_mlopsis already provided in thepipeline-server-config.jsonfor this demonstration with the Worker Safety Gear Detection sample app.Ensure that the pipeline inference element such as gvadetect/gvaclassify/gvainference should not have a
model-instance-idproperty set. If set, this would not allow the new model to be run with the same value provided in the model-instance-id.Navigate to the
[WORKDIR]/edge-ai-suites/manufacturing-ai-suite/industrial-edge-insights-visiondirectory and set up the app.cp .env_worker_safety_gear_detection .env
Update the following variables in
.envfileHOST_IP= # <IP Adress of the host machine> MR_PSQL_PASSWORD= #PostgreSQL service & client adapter e.g. intel1234 MR_MINIO_ACCESS_KEY= # MinIO service & client access key e.g. intel1234 MR_MINIO_SECRET_KEY= # MinIO service & client secret key e.g. intel1234 MR_URL= # Model registry url. Example http://<IP_address_of_model_registry_server>:32002 MTX_WEBRTCICESERVERS2_0_USERNAME= # Webrtc-mediamtx username. e.g intel1234 MTX_WEBRTCICESERVERS2_0_PASSWORD= # Webrtc-mediamtx password. e.g intel1234
Run the setup script using the following command
./setup.sh
Bring up the containers
docker compose up -d
Check to see if the pipeline is loaded is present which in our case is
worker_safety_gear_detection_mlops../sample_list.sh
Modify the payload in
apps/worker-safety-gear-detection/payload.jsonto launch an instance for the mlops pipeline[ { "pipeline": "worker_safety_gear_detection_mlops", "payload":{ "source": { "uri": "file:///home/pipeline-server/resources/videos/Safety_Full_Hat_and_Vest.avi", "type": "uri" }, "destination": { "frame": { "type": "webrtc", "peer-id": "worker_safety" } }, "parameters": { "detection-properties": { "model": "/home/pipeline-server/resources/models/worker-safety-gear-detection/deployment/Detection/model/model.xml", "device": "CPU" } } } } ]
Start the pipeline with the above payload.
./sample_start.sh -p worker_safety_gear_detection_mlops
Upload a model to Model Registry#
The following section assumes Model Registry microservice is up and running.
For this demonstration we will be using Geti trained worker safety gear detection model. Usually, the newer model is the same as older, architecture wise, but is retrained for better performance. We will using the same model and call it a different version.
Download and prepare the model.
export MODEL_URL='https://github.com/open-edge-platform/edge-ai-resources/raw/758b7a1e2edd021f3e6e51c72eb785c53ffa37f6/models/worker-safety-gear-detection.zip' curl -L "$MODEL_URL" -o "$(basename $MODEL_URL)"
Run the following curl command to upload the local model.
curl -L -X POST "http://<HOST_IP>:32002/models" \ -H 'Content-Type: multipart/form-data' \ -F 'name="YOLO_Test_Model"' \ -F 'precision="fp32"' \ -F 'version="v1"' \ -F 'origin="Geti"' \ -F 'file=@<model_file_path.zip>;type=application/zip' \ -F 'project_name="worker-safety-gear-detection"' \ -F 'architecture="YOLO"' \ -F 'category="Detection"'
NOTE: Replace model_file_path.zip in the cURL request with the actual file path of your model’s .zip file, and HOST_IP with the IP address of the host machine.
Check if the model is uploaded successfully.
curl 'http://<HOST_IP>:32002/models'
Steps to use the new model#
List all the registered models in the model registry
curl 'http://<HOST_IP>:32002/models'
If you do not have a model available, follow the steps here to upload a sample model in Model Registry
Check the instance ID of the currently running pipeline to use it for the next step.
curl --location -X GET http://<HOST_IP>:8080/pipelines/status
NOTE- Replace the port in the curl request according to the deployment method i.e. default 8080 for compose based.
Restart the model with a new model from Model Registry. The following curl command downloads the model from Model Registry using the specs provided in the payload. Upon download, the running pipeline is restarted with replacing the older model with this new model. Replace the
<instance_id_of_currently_running_pipeline>in the URL below with the id of the pipeline instance currently running.curl 'http://<HOST_IP>:8080/pipelines/user_defined_pipelines/worker_safety_gear_detection_mlops/{instance_id_of_currently_running_pipeline}/models' \ --header 'Content-Type: application/json' \ --data '{ "project_name": "worker-safety-gear-detection", "version": "v1", "category": "Detection", "architecture": "YOLO", "precision": "fp32", "deploy": true, "pipeline_element_name": "detection", "origin": "Geti", "name": "YOLO_Test_Model" }'
NOTE- The data above assumes there is a model in the registry that contains these properties. Also, the pipeline name that follows
user_defined_pipelines/, will affect thedeploymentfolder name.View the WebRTC streaming on
http://<HOST_IP>:<mediamtx-port>/<peer-str-id>by replacing<peer-str-id>with the value used in the original cURL command to start the pipeline.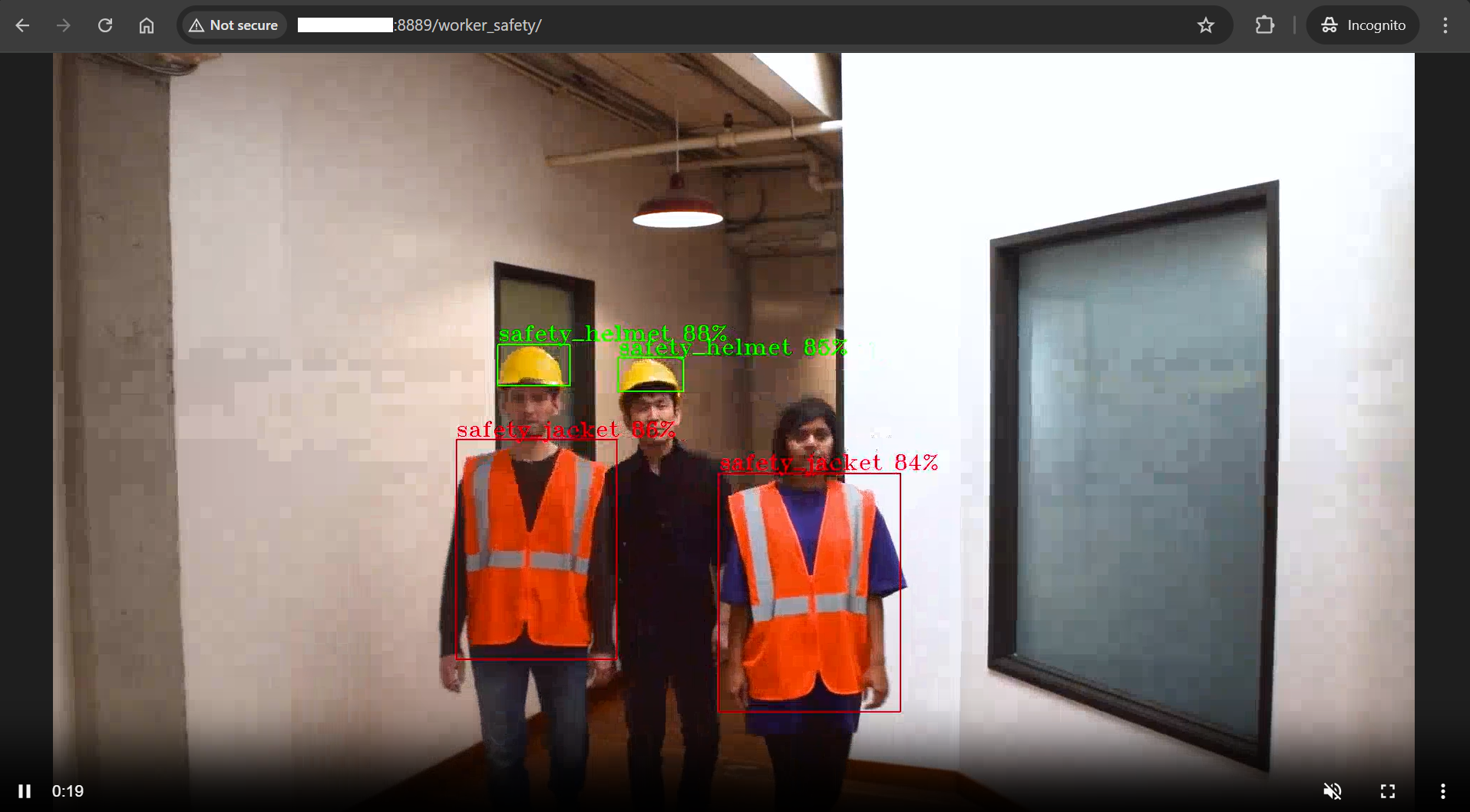
You can also stop any running pipeline by using the pipeline instance “id”
curl --location -X DELETE http://<HOST_IP>:8080/pipelines/{instance_id}